




Deep metric learningについて(理論①)

この記事の目次
はじめに
今回はその性能と汎用性の高さから、様々な分野で応用が進んでいるDeep Metric Learning理論について紹介していきたいと思います。
※loss function以降数学の内容がかなり多いので理解しにくいかもしれません。
Metric Learningとは?の理解をしたい方はLoss functionまで読んでいただけると何となくMetric Learningについて理解できると思います。
目的
- Metric Learningの知識をみにつけたい
- 今後様々なタスクに応用できそうな技術なので、その知識を蓄えたい
Metric Learnintとは
そもそも機械学習における距離とは
距離(きょり、distance)とは、ある2点間に対して測定した長さの量(Wikipedia参照)です。
日常的な使い方としては、二つ場所間の距離を測る際にキロメートルを利用します。
新宿→竹橋の距離は11.4km
より抽象的な距離:
GeForce RTX 2060 superと GeForce RTX 3060の価格差約1万円程度
(一応価格も距離であると認識すると後の記事を理解しやすいと思います。)
個人的には「何かを測る際の単位」が距離である、という感じで理解しています。
機械学習にもデータ間の距離をどうやって測定するかという問題はよくあります。
一般的に測定可能なデータの場合、ユークリッド距離(ED)、正弦波、およびその他の方法で直接行うことができます。 しかし、ビデオと音楽の間の距離を測定や、センテンス間の距離を測定するなど、より幅広いなデータに対しては上記の手法で距離を測ることは困難です。
例:顔の類似度(簡単)、履歴書の類似度(難しい)など
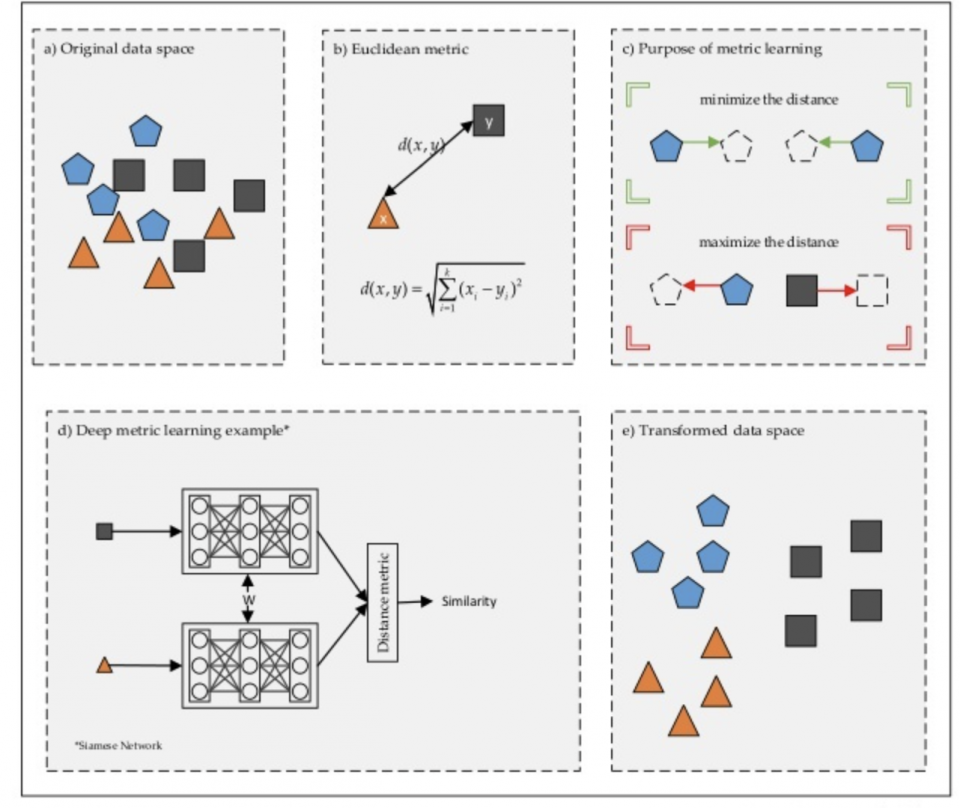
metric learningとは
metric learningの正式名称はDistance metric learningです。
つまり機械学習の形式でトレーニングデータに従って、特定のタスクに基づいて計量関数を自動的に構築することです。
定番のクラス分類と距離学習によるクラス分類の違いは、特徴量抽出部分を学習させる手法にあります。
metric learningは元データの変換や特徴を学習して、変換されたデータが特定のタスクに特定の類似性の尺度を満たすことができるようにします。ここでの尺度は、cosine similarity,overlap similarity,jaccard similarityなど、もしくは複雑な文章間の類似度や感情の類似性など測る尺度です。
Metric Learningのタイプ
メトリック学習は主に下記の二つタイプ分けられています
- 教師あり学習 (Supervised Learning)
同じラベルデータの距離を近づけ、異なるラベルデータの距離を遠ざけることができる距離を学習することです。center loss、amsoftmaxなどをよく使っています。
center lossでは各クラスにcenter featureを算出します。それによってクラス内の距離が狭くなります。center featureはクラス内の距離のみ関与するため、通常はsoftmaxやcross entropy loss損失と組み合わされ、カテゴリを分離しながら、クラスの距離を短くすることができます。
amsoftmaxはsoftmaxに基づいて改善されていますが、softmaxとは異なります。カテゴリを分離可能にするだけでなく、クラス内の距離を狭め、クラス間の距離を広げることができます。
※もちろん教師データの処理によってWeakly SuperVised Learningをさせることも可能です。検証はまだしていませんが、個人的は負例のデータを一緒に学習させるとクラス間の距離もっと遠ざけることができると思います。 - 弱教師あり学習 (Weakly Supervised Learning)
こちらの学習データは教師あり学習の手法とは少し異なり、タプル・トライアドのデータペアを学習します。正例のペアと負例のペアを事前に用意して、学習際に正のペアを近づけ、負のペアを遠ざけるによってデータ間のメトリックを学習します。
弱教師あり学習では、contrastive loss(対照損失)とtriplet loss(トリプレット損失)をよく使います。
上記で紹介した各lossは、後に詳しく説明したいと思います。
Deep Metric Learningとは?
実際にDeep Metric Learningでは、レコメンド、NLP、画像処理の分野などの領域よく利用されています。
Deep Metric Learningは、representation learning(参考サイト)のブランチです。
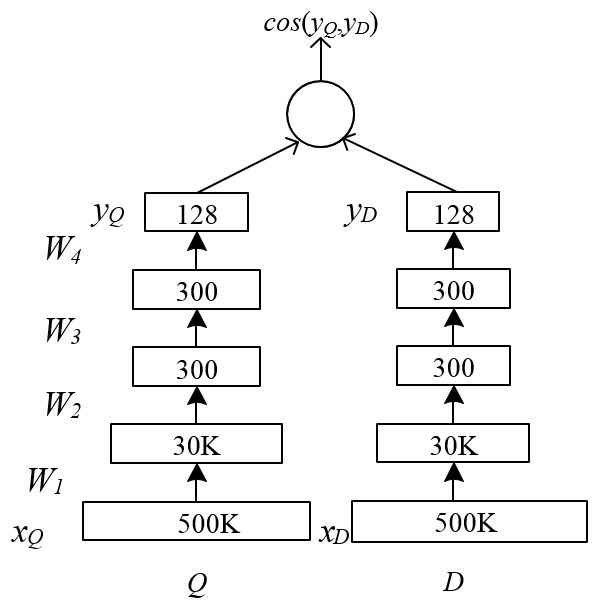
レコメンド領域有名なDSSMネット構造、最後の一層はCosより距離計算しています
従来の機械学習手法では、生データ処理機能によって制限されています。 したがって、分類またはクラスタリングタスクの前に前処理や特徴抽出ステップなどの特徴エンジニアリングが必要です。 これらのステップには専門知識が必要になります。
一方、深層学習は生データから学習できるという強みを持っています。従来の機械学習手法とは異なり、ディープラーニングはデータ量が少ないと十分に成功しないため、成功する結果を得るには大量のデータが必要です。
個人的理解を一言でまとめると、ペア特徴持っているデータに対して距離特徴を持っているembeddingを作成できる仕組みです。
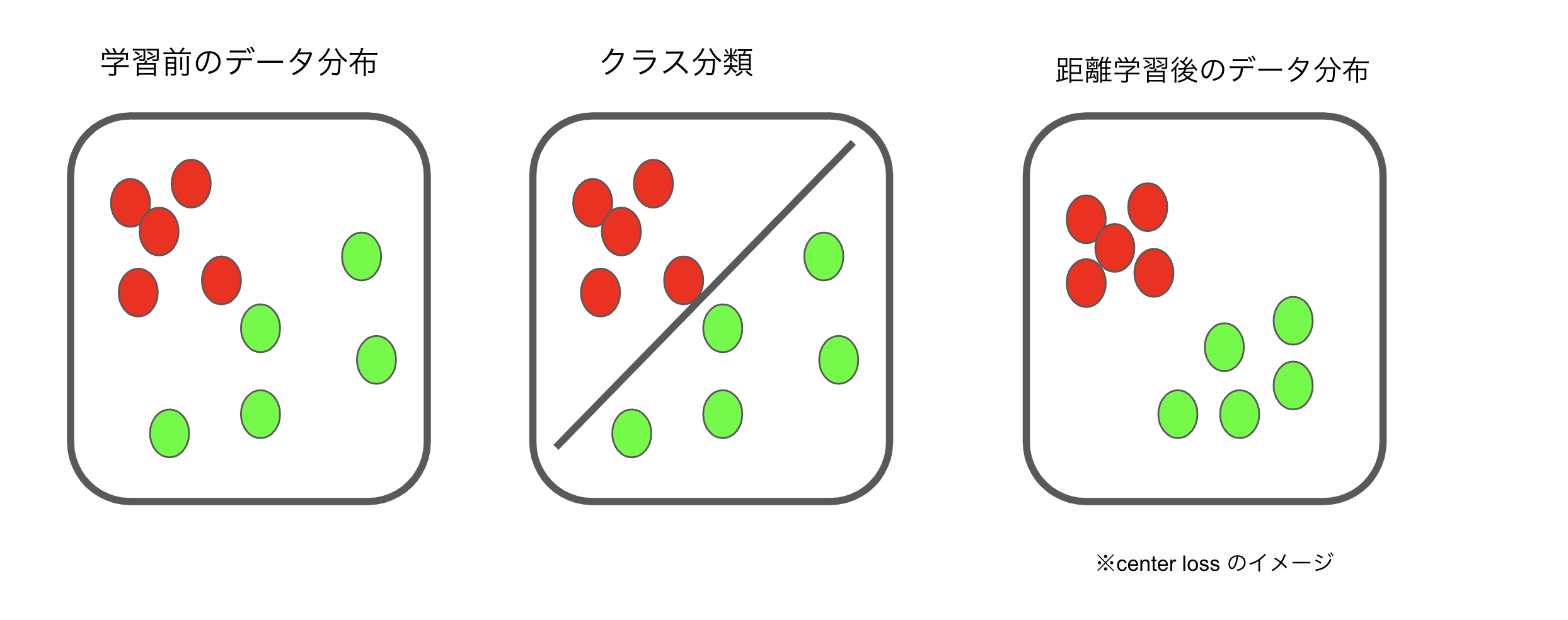
Deep Metric Learningイメージ
- a)生のデータ分布
- b)ユークリッド 距離計算
- c)意図的にデータを準備する
- d) 同じニューラルネットワークで同じラベルのデータ間の距離を最小化学習させ、異なるラベルのデータ間の距離を最大化させ距離を測る
- 上記の学習結果よりデータ間の距離を再定義します
Deep Metric Learning step(pipeline)
深層距離学習pipelineは主に3つで構成されています。
- 学習データの準備と処理
- ニューラルネットワークの設計
- 損失関数の選択(タスクやデータ構造を考慮しつつ)
同じラベルのデータの距離の最小化や、異なるラベルのデータ間の距離を最大化する仕組みはDeep Metric Leanringの最もコアの部分であり、上記の仕組みでは主に損失関数の設計や選択で実現しています。
入力するサンプルは、Deep Metric Learningの成功を改善するための最も重要な要素の1つであり、サンプルの組み合わせの選択はモデル訓練の成功と収束性に大きな影響を与えます。
loss functionについて
いろんな文献や記事を読むとMetric Learningで一番重要なのはLoss functionであると書かれてあります。そのため、今回はLoss functionについて書かれた論文や記事を個人の観点でまとめようと思います。
弱教師あり学習
contrastive loss
contrastive lossは2006年に発表された「Dimensionality Reduction by Learning an Invariant Mapping」において、次元削減操作を行うものとして提案されています。この論文中にMetric Learningというワードは登場しませんが、距離を学習させて次元削減を実現します。
contrastive lossの考え方は、類似したサンプル間の距離と異なるサンプル間の距離を独立して短くすることです。
2つのサンプルiとjが1つのラベルの場合、y_ij=1。この時点で、Lossはこの二つサンプルの距離である
iとjが異なるラベルの場合、y_ij = 0 その時点のlossは、
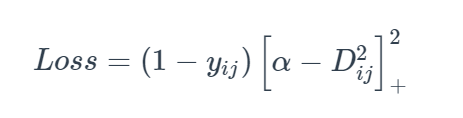
d > αになるよう学習させます。
contractive loss全体像
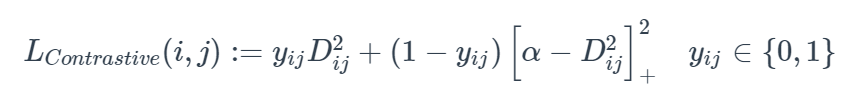
triple loss
2015年に発行された「FaceNet: A Unified Embedding for Face Recognition and Clustering」で、顔の分類タスクにTriple lossを使用することが提案されています。
Triplet lossでは3組の入力データのpositiveペアとnegativeペアの相対距離を算出し、それにマージンをかけます。つまり、Contrastive lossではnegativeペアをマージンmの距離よりも離れるように学習させることですが、Triplet lossではnegativeサンプルとの距離をpositiveサンプルとの距離よりもマージンmの距離以上に遠くなるよう学習させることです。同時に、intra-classのサンプルを引き寄せてinter-classのサンプルを離れようとすることができます。現在でも広く使われている距離学習手法のようです。
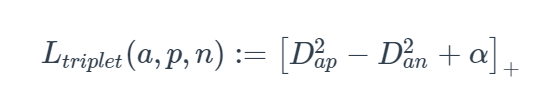
a: anchor
p: Positive
n: Negative
D_ap: anchor とPositiveの距離
α : Margin
Triple Lossの要素
教師あり学習
center loss
center Lossは2016年に「A Discriminative Feature Learning Approach for Deep Face Recognition」より提案されたものです。
Metric Learningは、単純にsoftmaxやcross entropy lossを利用することに制限があります。この二つ方法によりカテゴリを分離が可能ですが、同じクラス内の距離を狭めることはできません。
Metric Learningにおいて、クラスを分離できるだけでなく、クラス間を区別することも学習する必要があります。
そこでcenter Lossが提出されました。center lossは、センタークラスタリングとsoftMaxクラス間損失のコアアイデアを利用し、センタークラスタリングのクラス内制約とsoftMaxのクラス間制約を実行します。訓練時にはsoftmax lossに加算した損失関数(Ltotal)を使われています、同様の特徴もつデータがクラスの中心点の周りにクラスター化して、クラス間距離を拡大し、クラス内距離を短縮し、より識別力のある深い特徴を学習します。
対応する損失関数は
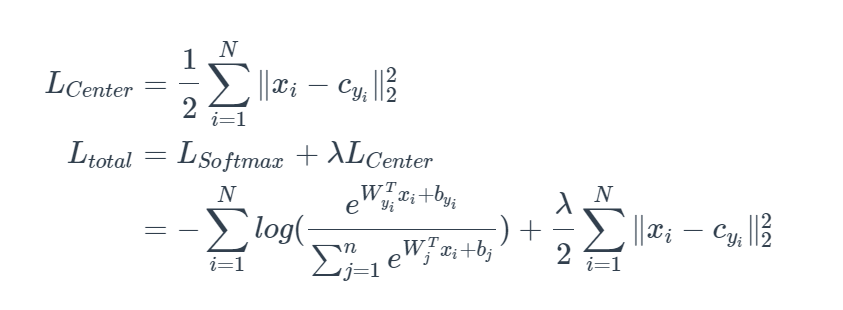
cyiはデータの正解クラスの中心位置です。各クラスの中心位置はmini-batchごとで更新されます
▼softmax cross entropy lossから得られた特徴量の可視化

AMSoftmax
こちらについては私も全は部理解できていません。。。
AMSoftmaxはSoftmaxより展開されたものですが、Metric Learningに特化したようなものでした。
論文ではAMSoftmaxはクラス間の距離を広げ、クラス内のデータ距離を狭めることが可能になり、クラス間の距離をTarget regionに狭めさせています。
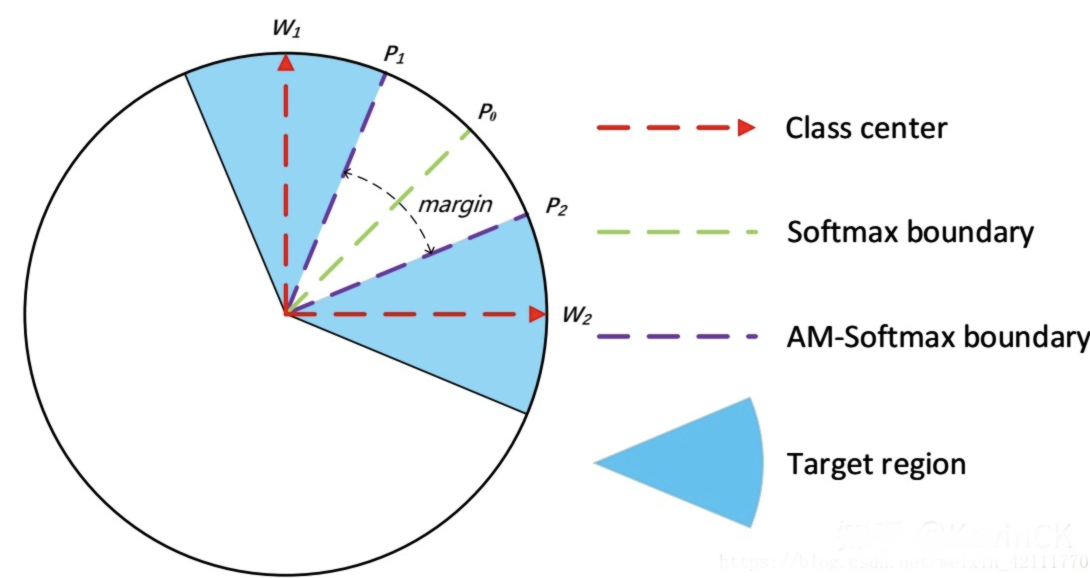
まとめ
今回はMetric Learning理論について、重要な部分と自分の感想をまとめました。
- 深層距離学習は、識別性の高い(discriminative)特徴量を得るためにディープニューラルネットワークを学習させる手法です。得られたモデルは特徴量抽出器として利用します。
- 学習手法はデータの形によって、教師あり学習と弱教師あり学習の二つに大きく分けられています。
- 損失関数の設計の他に、サンプル選択の設計も大事です。
- 画像やNLPなどいろんな領域に適応することが可能です。
なぜわざわざそういう難しい技術を学ぶのかというと、
距離を測るという技術がマイナビにとって重要であると思うからです。
この技術は文書間の類似度を測るだけでなく、他の文字データの距離も測られます。
つまり、この技術により我々が扱っているデータのレコメンドやマッチングに何か新しい観点で処理可能の技術になるかもしれないということです。
Metric Learningは近年大きな成果がありませんが、現在の結果から見ると距離を学習させるという概念がいくつかの領域で利用ができると思います。
近いうちに何かデータを利用して実践してみようと思います!!!
参考記事
深層距離学習(Deep Metric Learning)の基礎から紹介
Sampling Matters in Deep Embedding Learning
FaceNet: A Unified Embedding for Face Recognition and Clustering
MLAS: Metric Learning on Attributed Sequences
A Discriminative Feature Learning Approach for Deep Face Recognition
FaceNet: A Unified Embedding for Face Recognition and Clustering
Deep Metric Learning: a (Long) Survey
Deep Metric Learning: A Survey
A Discriminative Feature Learning Approachfor Deep Face Recognition
从Softmax到AMSoftmax(附可视化代码和实现代码)
顔認証におけるいろいろな損失関数(Loss function)
※本記事は2022年08月時点の情報です。

