




【AWS re:Invent2023セッションレポート】クラウドにおけるトラブルシューティング

この記事の目次
セッション概要
タイトル
SUP306 | Troubleshooting in the cloud
説明
How do you troubleshoot large-scale applications running on AWS? Using time-tested troubleshooting methodologies and AWS services to accelerate the diagnosis and resolution of operational issues, see how to use Amazon CloudWatch, AWS Config, AWS X-Ray, and AWS AI services to set up appropriate proactive and reactive monitoring and automated mitigations. In this workshop, choose your preferred domain (i.e., compute/networking, containers, databases, or serverless/DevOps), and then work on triaging issues using techniques and best practices shared during the workshop. Come learn how to securely approach troubleshooting at scale on AWS and use pre-trained AWS AI services to accelerate coding. You must bring your laptop to participate.
参考情報
会場がMGM Grandでしたが、VenetianのWorkshopより少し狭かったです。キャパが80人ちょっと?
この部屋だけなのかホテル全体の傾向なのかはわかりませんが。
満員御礼状態で、特に予約が多く、非予約の4番目くらいに並んでたんですが結構ギリギリで入れた印象です。
内容
アジェンダ
- Hear tips/methodologies for troubleshooting
- 観測サービス・ツール(AWS Nativeと外部SaaS)
- 対応方式
- 50/50 methods
- good vs. bad comparision method
- Controlled reproduction method
- Building timelines method
- Troubleshooting methodologies
- Should
- Should Avoid
- Workshop
Hear tips/methodologies for troubleshooting
- 観測に使うツール群
- クラウドのトラブルシューティングは多岐にわたり、それぞれの環境で効率的なトラブルシュートを行う必要がある
- アーキテクチャ、クラウド設定、アプリ、観測、カナリアテスト・デプロイ、ログ
- トラブルを正確に定義し、理解する
- 分析にあたってはいくつかの手法があり、一つ或いは複数の方法を使う
- 「網羅ではない」ところがミソ。
- 将来再発した際の問題解決時間を短くするために、手法の間違いは継続的に正していく
- 分析手法
- 50/50 methods
- 開始点と終了点の間でプロセスを半分(50/50)に分割し、トラブルが中間点で発生するかどうか確認
- 発生しているところを再度半分に分割し、中間点でトラブルが発生するかどうかを確認
- 以下繰り返していくことで問題箇所を特定する
- 例: PrivateLink→NLB→ALB→ECS/EKS/Lambda→DB/外部サービス…と言った構成の場合
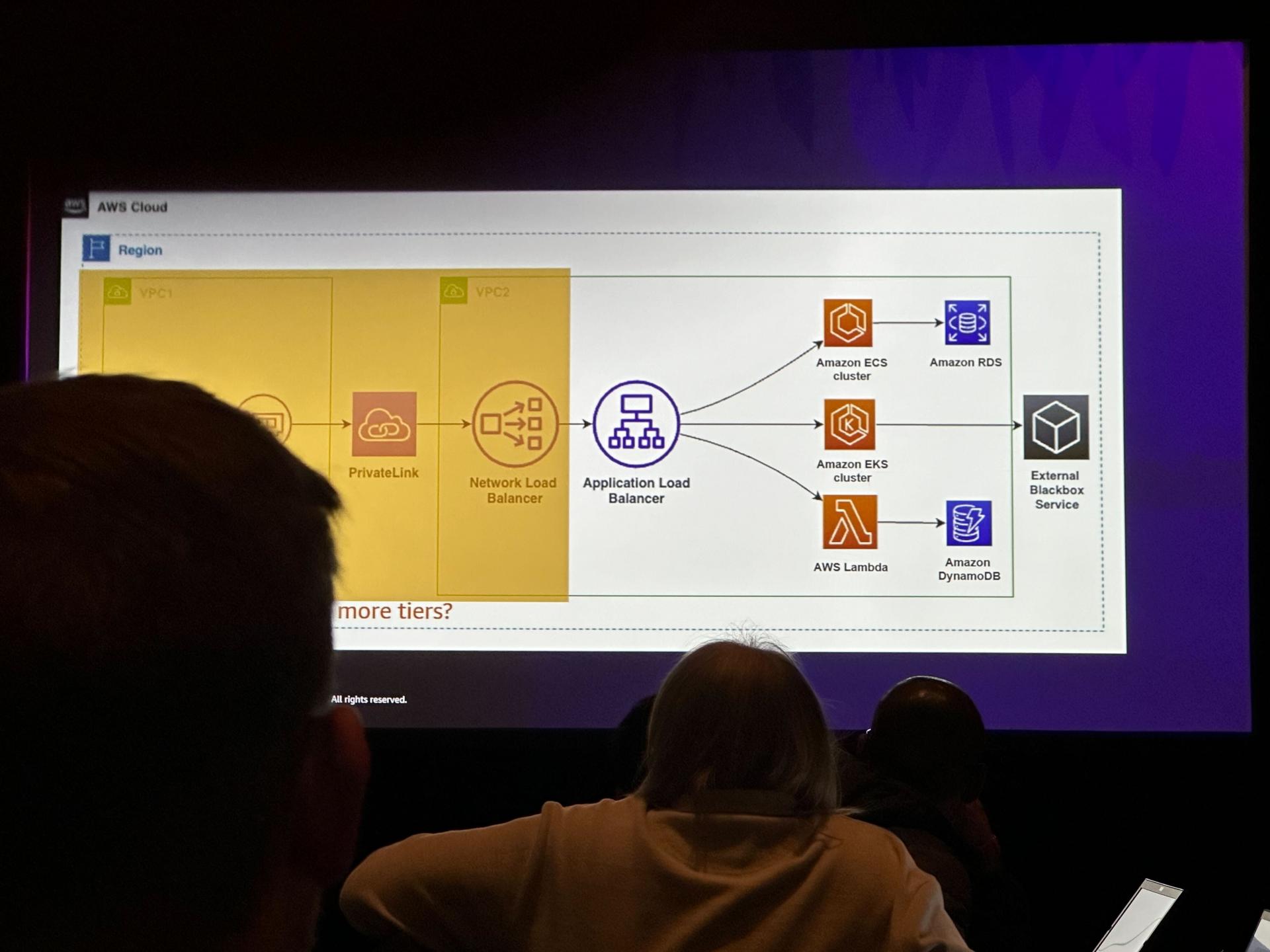
- good vs. bad comparision method
- 2つの似た環境の内片方で問題が起きている場合に、設定値やリソース利用状況を比較して原因を特定する
- 標準化が進めばこの方式が使われることが増えそう
- 2つの似た環境の内片方で問題が起きている場合に、設定値やリソース利用状況を比較して原因を特定する
- Controlled reproduction method
- ある程度自由にコントロールの効く環境に同じものを再現し、弄り回して原因を特定する
- 別リージョンや別アカウントにデプロイしてみる等
- Sandbox環境があればそれを使うのもあり
- 例: CodePipelineでCloudFormationを使ってSAMをデプロイするのに失敗する場合、問題のテンプレートを別アカウントで直接デプロイしてみるなど
- ある程度自由にコントロールの効く環境に同じものを再現し、弄り回して原因を特定する
- Building timelines method
- 「いつ問題が発生したか」と「そのタイミングで何の変化があったか」を整理して問題を特定する
- 問題発生のタイミングや期間に合わせてその時の設定を適用して追跡
- 場合によってはロールバックで解決できる
- 50/50 methods
- Should
- 何らかのパターンを示す数値がないか細心の注意を払う
- 問題解決後は5つ「なぜ?」を追求して振り返る
- 各計測値のパーセンタイルをきちんと理解する
- 内外のチームに、ログやメトリクスの改善による透明性を求める
- メトリクスが示す意味について透明性を追求する
- Trust but Verify. 信頼はするが検証する。
- Should avoid
- 確証バイアス
- これまで検証した内容を追跡しないまま場当たり的なトライ&エラーを繰り返す
- 一度に複数のものを変更する
- データの裏付け抜きに2つのできごとや事象に相関関係を見出そうとする
- 原因と結果の混同・逆転
- 自分が今見えている範囲のメトリックしか見ない
- 原因は別のところにある可能性を常に考慮するべき
- 問題が起きるまで監視基盤の構築を先延ばしにする
- 関連資料


Workshop
- 4つのテーマでラボが用意されており、どれか1つを選択して着手する方式
- Networking and Web services
- DevOps and serverless
- Containers
- Database
- 今回はDevOps and serverlessを選択
- NetworkingやDatabaseの方が既存の知識は活かせそうだったが、折角なのでより今後に活かせそうな方にしました
- ちなみにre:Invent後も続きはできる模様

- 折角なので全部やってまたまとめたいと思います
Devops and serverless
- 対象の構成
- Code PipelineでSAMスタックをデプロイしている構成
- PipelineはCodeCommitからソースを引っ張ってCodeBuildでSAMテンプレートからCFnテンプレートをビルドしてCodeDeployでデプロイする構成
- SAMアプリはAPI GatewayとLambdaとDynamoDBでユーザーデータの登録と取得を行うもの。言語はJS。
- Code PipelineでSAMスタックをデプロイしている構成
- CodePipelineに3つ、SAMアプリに3つそれぞれ問題があり、順に解決していく
- CodePipelineは直接編集する権限がなく、CodePipeline用のCFnスタックを修正して対応する
- ここが地味に面倒で時間を食った。Cloud9の利用が推奨されており環境が用意されていたが、そこにCodePipeline用のCFnテンプレートがなく直接中身を確認するしかない・デプロイ時にいちいちダウンロードとアップロードをする必要があるなど。
- 家でやる場合は最初からローカルで環境作った方が楽そう。
- Source、Build、Deployそれぞれに一箇所ずつエラーの原因となる要素があり、それらを自力で特定して改善する
- ひとつ一つは「まぁよくあるアレだよね」みたいなノリでサクッと特定できる内容で、環境の操作で時間はかかってもそこまで高度ではない印象
- SAMアプリの3つの課題のうち1つ目が終わったあたりで時間切れ。
- あとで再トライしたら続き書きます。
- CodePipelineは直接編集する権限がなく、CodePipeline用のCFnスタックを修正して対応する
所感・まとめ
- これまで受けたWorkshopの中でもかなり充実した部類
- 前説でこれまで頭の中でごちゃっとしていたトラブル対応手法がかなり整理された
- 「新しいことを知る」より「整理する・網羅する」趣が強いためか、比較的英語も理解できました。
- スピーカーのうち1人がそれなりに早口だったため、そこだけはほぼフィーリングでしたが…
- 「新しいことを知る」より「整理する・網羅する」趣が強いためか、比較的英語も理解できました。
- Workshop本番も、ヒントや回答も用意されているものの、多少の経験があれば自力で辿り着ける良い塩梅でした
- 前説でこれまで頭の中でごちゃっとしていたトラブル対応手法がかなり整理された
- 分析手法の選択肢には事前の準備が無ければできない物があり、共通基盤の管理部門としてはここを全体に提供することでトラブル対応の工数を減らせそう
- 例えばControlled reproduction methodはSandbox環境がカジュアルに提供できれば選択肢としての有用性がぐんと上がる
- トラブル対応時にはどうしても焦りのせいで手当たり次第に色々やりがちだが、順序立てた対応の重要性が改めて整理できた
- 「トラブルが起きてからではなく予め追跡ができるよう監視基盤は作れ」というのは、肌で感じないと中々実行できないものだが、こうしたハンズオンでログやメトリクスの有り難さを感じて定期的に意識を高めておく必要があると感じた
※本記事は2024年01月時点の情報です。

