




~マイナビエンジニアからの挑戦状 vol.3~の解説を公開します!

この記事の目次
概要
こんにちは!システム統括本部(現デジタルテクノロジー戦略本部)のS.Dです。
競プロが趣味の私が作成した、オリジナル問題をクリアされた方には、開発エンジニア向けのインターンシップに招待させていただく企画を開催しました。
-

2022/05/12
毎年大人気の本企画を、今回も実施します!マイナビのエンジニアが考えた問題を解けた方には、夏に開催されるインターンシップに特別招待させていただきます。ぜひ挑戦してみてください!
お知らせ
たくさんのご回答ありがとうございました!!
6月3日(金)17:00をもちまして、回答受付は締め切らせていただきました。
本記事では、解説を載せていきたいと思います。
問題1
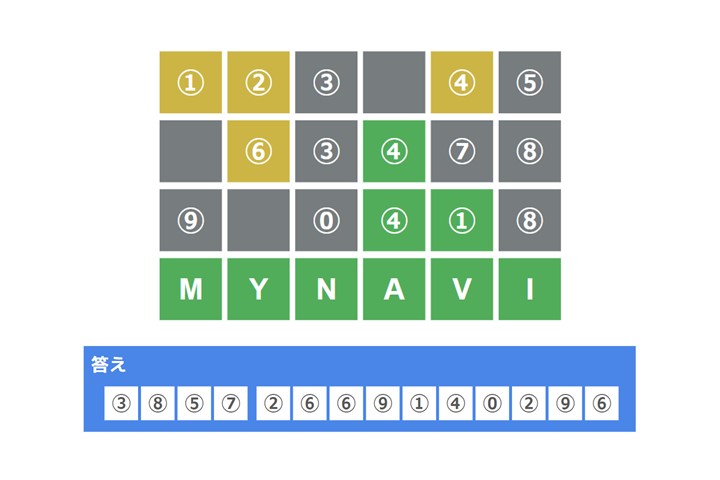
ヒント→https://www.google.com/search?q=wordle
回答をフォームに入力し、提出してください。
問題1の解説
解法
まず問題の意味について理解することが重要です。ヒントから問題図はWebサービス「Wordle」のオマージュだと推測できます。Wordleの逆手法で各マス目の文字を特定し、マスの⓪~⑨にあたる文字を、答えの⓪~⑨に照らし合わせることで答えが得られそうです。
Wordleとは?
「Wordle」は英単語当てゲームです。単語を入力すると 緑、黄、灰の3色の手がかりが得られます。それを元に正解となる英単語を推測していきます。
緑色は、正解の英単語に含まれていて、その位置も同じ場合。
黄色は、正解の英単語に含まれていて、その位置が異なる場合。
灰色は、正解の英単語に含まれていない場合です。
参考図: 《公式ルールページから》
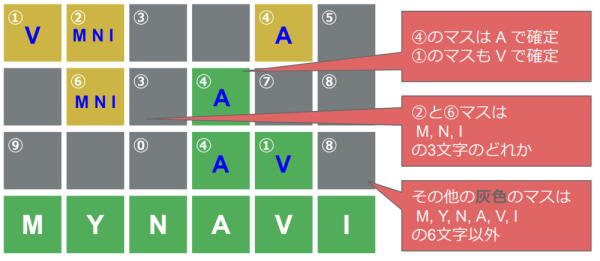
初期分析する
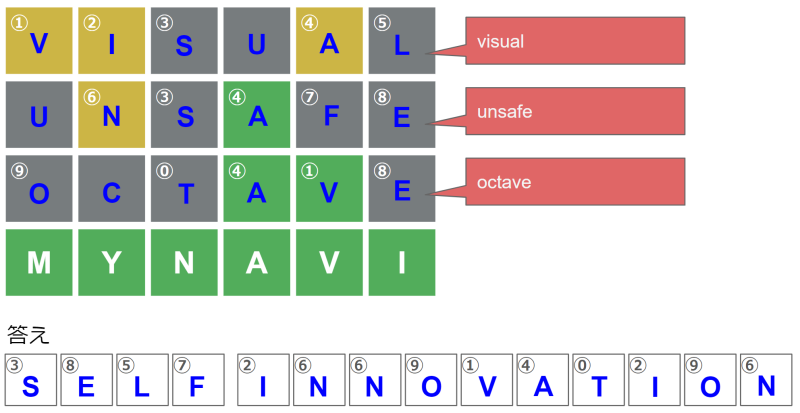
問題をWordleに見立ててると、4回目の入力で「MYNAVI」という正解の英単語にたどり着いたようです。
- ④は2行目4文字目で緑色マスとなっているため、正解の英単語「MYNAVI」の4文字目の「A」と特定できます。
- ①は3行目5文字目で緑色マスとなっているため、正解の英単語「MYNAVI」の4文字目の「V」と特定できます。
- ②は1行目2文字目で黄色マスとなっています。正解の英単語「MYNAVI」に含まれていて、既に確定している「A」「V」ではなく、位置が同じ「Y」ではない文字「M」「N」「I」の3種類のどれかであることが分かります。
- ⑥は2行目2文字目で黄色マスとなっています。これも②と同様に「M」「N」「I」の3種類のどれかであることが分かります。
- 他の灰色のマス目は「M」「Y」「N」「A」「V」「I」のどれでもない文字になります。
参考図: 《初期分析》
各行の英単語を推測する
一部の文字が特定されている英単語探しは、クロスワードパズルの要領で解くことができます。
幸いネット上には英単語クロスワードパズルを解くサポートサービスがあります。それを利用して英単語を推測していきます。
ここでは、Crossword Clue Solver を活用していきます。
3行目の英単語を推測する
3行目の英単語は、4文字目が「A」、5文字目が「V」の6文字の英単語です。
Crossword Clue Solver でその条件に合致する単語を検索すると、behave, casava, cleave, encave, excave, greave, impave, mohave, mojave, octave, octavo, sclave, sheave, sleave, theave, thrave, vltava, zouave の18単語が検索されます。
参考図: https://www.crosswordsolver.org/solve/---av-
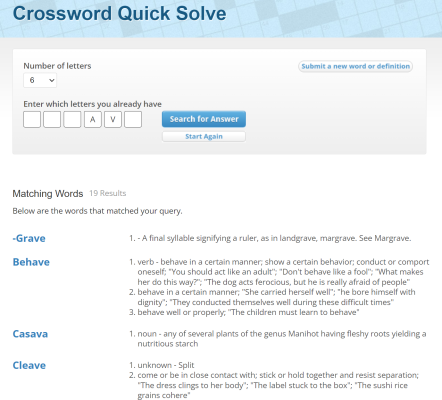
この18単語のなかで、【1文字目、2文字目、3文字目、4文字目が全て異なる「M」「Y」「N」「A」「V」「I」以外の文字】という条件に当てはまるものは octave, sclave, thrave, zouave の4単語に絞られます。
→ それにより、3行目の英単語の6文字目は「E」と特定されます。また⑧以外の灰色マスは「M」「Y」「N」「A」「V」「I」「E」以外の文字となります。
参考図: 《3行目推測》
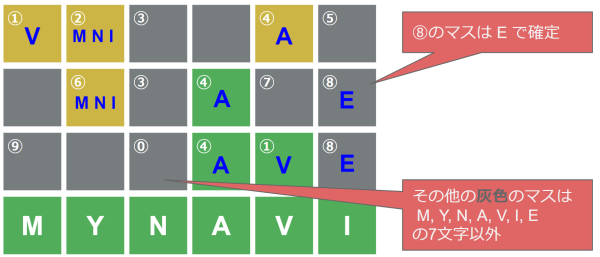
1行目の英単語を推測する
1行目の英単語は、1文字目が「V」、2文字目が「M」「N」「I」、5文字目が「A」、他が「M」「Y」「N」「A」「V」「I」「E」以外の文字からなる6文字の英単語です。その条件に合致する英単語をCrossword Clue Solverで検索します。
- https://www.crosswordsolver.org/solve/vm--a-
- https://www.crosswordsolver.org/solve/vn--a-
- https://www.crosswordsolver.org/solve/vi--a-
以上の3つのURLの検索結果から、violas virgas visual vithar の4つの英単語に絞られます。
→ ②は「I」と特定できました。同時に⑥は「M」「N」のどちらかに、③は「O」「R」「S」「T」の4種類に絞られました。
参考図: 《1行目推測》
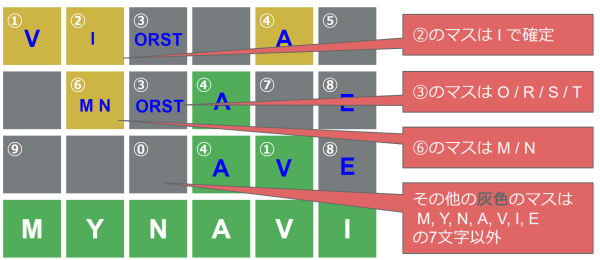
2行目の英単語を特定する
今まで同様に2行目の英単語を推測します。
条件に合致する英単語は unsafe のみです。
→ ⑥は「N」、③は「S」、⑦は「F」に特定できました。また残りの灰色マスは「M」「Y」「N」「A」「V」「I」「E」「S」「F」以外の文字となります。
参考図:《2行目特定》
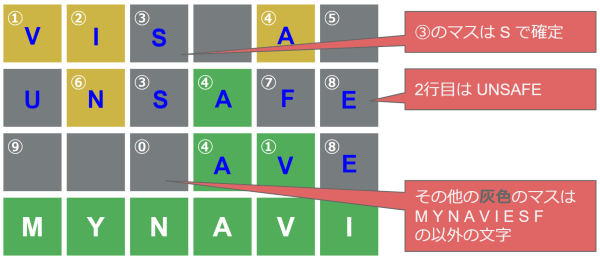
1行目の英単語を特定する
同様に1行目の英単語を推測します。
条件に合致する英単語は visual のみです。
→ ⑤は「L」に特定できました。残りの灰色マスは「M」「Y」「N」「A」「V」「I」「E」「U」「S」「F」「L」以外の文字となります。
参考図:《1行目特定》
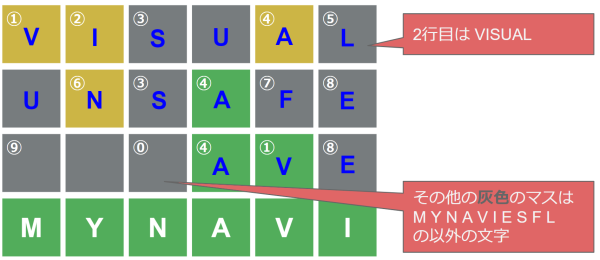
3行目の英単語を特定する
「3行目の英単語を推測する」から 3行目の英単語は octave, sclave, thrave, zouave の4つに絞られていました。
それ以後の考察により、sclaveは1文字目に「S」が含まれており選択肢から外れます。zouaveも3文字目に「U」が含まれており選択肢から外れます。3行目の英単語は octave と thrave の2つに絞られました。
ここで2つ場合について、答えを見ていきます。
3行目の英単語が thrave の場合
3行目の英単語が thrave の場合、各文字は以下のとおりとなります。
⓪「R」 ①「V」②「I」③「S」④「A」⑤「L」⑥「N」⑦「F」⑧「E」⑨「T」
それを答えに対応させると

SELFINNTVARITN ・・・英語として微妙です
3行目の英単語が octave の場合
3行目の英単語が octave の場合、各文字は以下のとおりとなります。
⓪「T」 ①「V」②「I」③「S」④「A」⑤「L」⑥「N」⑦「F」⑧「E」⑨「O」
それを答えに対応させると

SELFINNOVATION ・・・英語として成立しています。これが解答となります。
別解 (プログラムで解く)
クロスワードパズルの要領で解いてきましたが、エンジニアらしくプログラムを書いて解くこともできます。
下はパブリックドメインの英和辞書データ (https://github.com/kujirahand/EJDict) を利用して、問題文にマッチするものを総当たりで解くプログラムです。
import urllib.request
import string
# 6文字英単語リスト
len6_word_list = []
# パブリックドメインの英日辞書から、6文字の英単語を収集する
for ch in string.ascii_lowercase:
resp = urllib.request.urlopen(f"https://raw.githubusercontent.com/kujirahand/EJDict/master/src/{ch}.txt")
for line in resp.read().decode("utf-8").split("\n"):
word = line.split("\t")[0].lower()
if len(word) == 6 and all(c in string.ascii_lowercase for c in word):
len6_word_list.append(word)
# 問題文の1行目~3行目に合致する可能性のある英単語を列挙する
line_words = [
# 1行目の英単語
[w for w in len6_word_list if w[0] == "v" and w[1] in "mni" and w[4] == "a"],
# 2行目の英単語
[w for w in len6_word_list if w[1] in "mni" and w[3] == "a"],
# 3行目の英単語
[w for w in len6_word_list if w[3] == "a" and w[4] == "v"],
]
# 全探索
for w1 in line_words[0]:
for w2 in line_words[1]:
for w3 in line_words[2]:
# 一行目の英単語の3文字目は二行目の英単語の3文字目と一致 → ③
if w1[2] != w2[2]: continue
# 二行目の英単語の6文字目は三行目の英単語の6文字目と一致 → ⑤
if w2[5] != w3[5]: continue
# ⓪~⑨のアルファベット
answer_chars = w3[2], w1[0], w1[1], w1[2], w1[4], w1[5], w2[1], w2[4], w2[5], w3[0]
# ⓪~⑨のアルファベットはそれぞれ異なる
if len(set(answer_chars)) != 10: continue
# 一行目の英単語の4文字目は⓪~⑨のアルファベット以外
if w1[3] in answer_chars: continue
# 二行目の英単語の1文字目は⓪~⑨のアルファベット以外
if w2[0] in answer_chars: continue
# 三行目の英単語の2字目は⓪~⑨のアルファベット以外
if w3[1] in answer_chars: continue
# すべての条件を満たす場合に、答えとして出力
print(w1, w2, w3, answer_chars, sep="\n")
print(*[answer_chars[int(x)] for x in "38572669140296"], sep="")→ Google Colab 版は こちら
解答まとめ
⓪「T」 ①「V」②「I」③「S」④「A」⑤「L」⑥「N」⑦「F」⑧「E」⑨「O」
1行目の英単語 visaul, 2行目の英単語 unsafe, 3行目の英単語 octave
答えは「SELF INNOVATION」となります。
問題作者から
この問題は、マイナビのシステム部門で流行っている Wordle をモチーフに作成した問題です。
社内チャットのslack上には #wordle 専用のチャンネルがあり、毎日どれだけ短い手数で英単語を当てるかを競っています。
答えの「SELF INNOVATION」はマイナビの今年の新卒採用サイトのコンセプト「自分革新」を英訳したものです。この問題を解くことでマイナビの採用について興味を持ってもらえればと思い、「SELF INNOVATION」を答えとして選びました。
問題を作成するにあたって、Wordleの正解単語は「MYNAVI」、問の答えは「SELF INNOVATION」と始めから決めていました。
残りの英単語はなるべくエンジニアに馴染みのある単語にしたいと考えて、英単語辞書ファイルと自家製Pythonプログラムでシミュレーションを繰り返しました。「VISUAL」は開発で利用している Visual Studio Code、「UNSAFE」は Go言語の Unsafe Pointer、「OCTAVE」は プログラミング言語 GNU Octave から来ています。
実は答えが4文字と10文字で分かれていることに気づけば、後半の10文字の英単語は限られるため innovation と推測できる問題です。
それでも前半の4文字の英単語を推測するにはそれなりに時間がかかるかと思います。
問2の解法
考察
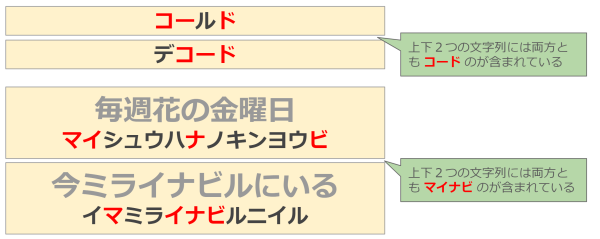
「コールド」と「デコード」の2つの文字列から答え「コード」が導かれ、「毎週花の金曜日」と「今ミライナビルにいる」の2つの文字列からら答え「マイナビ」が導かれています。「汝、文学と科学の力を信じよ」と「情報分析して改善アクション」から同じ法則を用いて導いたものが問2の解答のようです。
「コールド」と「デコード」にはどちらも「コード」を構成する文字「コ」「ー」「ド」の3文字がすべてこの順番で含まれています。「毎週花の金曜日」と「今ミライナビルにいる」をカタカナに変換した「マイシュウハナノキンヨウビ」「イマミライナビルニイル」にも「マイナビ」を構成する「マ」「イ」「ナ」「ビ」がこの順番で含まれています。どうやら2つの文字列の両方の部分文字列で最長のもの (最長共通部分文字列, Longest-common subsequence problem, LCS) が答えとなっているようです。
参考図:
最長共通部分文字列を求める
「汝、文学と科学の力を信じよ」と「情報分析して改善アクション」をカタカナに変換した「ナンジブンガクトカガクノチカラヲシンジヨ」と「ジョウホウブンセキシテカイゼンアクション」の最長共通部分文字列を求めていきましょう。

最長共通部分文字列を求める問題は典型的なアルゴリズム問題です。動的計画法を用いて解くことができます。詳細はウィキペディアの 最長共通部分列問題 を参考にしてください。今回はPython3.8で実装してみます。
プログラムソース:
from collections import defaultdict
from typing import Set
def lcs(x: str, y: str) -> Set[str]:
dp = defaultdict(lambda:set([""]))
for i in range(len(x)):
for j in range(len(y)):
if x[i] == y[j]:
dp[i, j] = set(r + x[i] for r in dp[i - 1, j - 1])
else:
rs = dp[i - 1, j] | dp[i, j - 1]
l = max(len(r) for r in rs)
dp[i, j] = set(r for r in rs if len(r) == l)
return dp[len(x) - 1, len(y) - 1]
def check(s1: str, s2: str):
result = lcs(s1, s2)
print(f"LCS({s1}, {s2}) -> {', '.join(result)}")
check("コールド", "デコード")
check("マイシュウハナノキンヨウビ", "イマミナイナビルニイル")
check("ナンジブンガクトカガクノチカラヲシンジヨ", "ジョウホウブンセキシテカイゼンアクション")最長共通部分文字列は解が複数の場合もあるため、関数lcsの戻り値は文字列Setとなっています。
実行結果:
LCS(コールド, デコード) -> コード
LCS(マイシュウハナノキンヨウビ, イマミナイナビルニイル) -> マイナビ
LCS(ナンジブンガクトカガクノチカラヲシンジヨ, ジョウホウブンセキシテカイゼンアクション) -> ジブンカクシン「ナンジブンガクトカガクノチカラヲシンジヨ」と「ジョウホウブンセキシテカイゼンアクション」の最長共通部分文字列は「ジブンカクシン」となり、これが問2の解答となります。
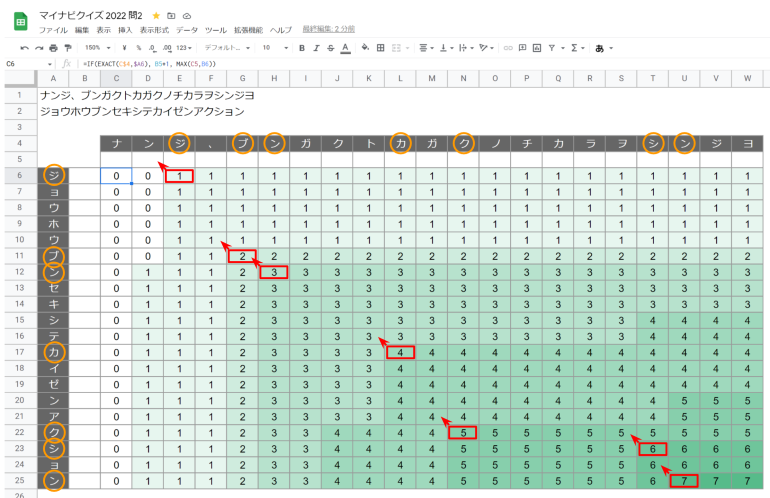
別解 (スプレッドシートを使って)
2つの文字列の最長共通部分文字列はスプレッドシートでも求めることができます。
下のようなマトリックスをつくり、右下から数字が増えるマスを左上にたどっていけば求められます。
実際のスプレッドシートはこちら → https://docs.google.com/spreadsheets/d/13EWfng0HVNFpljcqJ_0FDgJczLJLziW7I3VZ8x_1inY/edit#gid=0
問2の解答まとめ
問2の答えは「ジブンカクシン」(自分革新) となります。

問題作者から
もともと「マイナビエンジニアからの挑戦状」は第1問だけの想定で進めていました。社内で第1問をテスト公開したところ、「クロスワードパズルの要領で解ける」「プログラミングスキルが不要」などの意見が出てきました。そのため急遽アルゴリズム力を必要とするこの問題を第2問として追加しました。
第2問の解答は第1問と同じく今年のマイナビの新卒採用のテーマ「ジブンカクシン (自分革新)」となります。先に第1問を解いた人は自信をもって2問目の解答を提出できたと思います。
URL: https://www.mynavi.jp/saiyou/

問題文にある「ミライナビル」は、私たちシステム統括本部のオフィスがあるJR新宿ミライナタワーが由来です。私が所属しているシステム統括本部は昨年2021年11月にここに引っ越してきました。新オフィスでの業務生活についてはマイナビエンジニアブログにもエントリーがありますし、Twitter マイナビTech でも多く触れられています。
URL: https://twitter.com/mynavi_tech
問題を作成するにあたって、原案を考案していただいた若手エンジニアのS.Dさん、テスト協力や難易度調査など協力いただいた新卒エンジニアのS.Kさんをはじめ多くの方々にサポートしていただきました。全体的にバランスのとれた問題設計できたと思っています。ありがとうございました。
※本記事は2022年06月時点の情報です。

