




Vertex AI Trainingに入門してみる

この記事の目次
はじめに
こんにちは。AIシステム部のS.Tです。
AIモデルを作るための学習環境といえば、JupyterNotebookを思い浮かべる方も多いと思います。セルにコードを書き、順次実行して結果を確認しながらコーディングを進めることができるので、研究開発には持ってこいのツールとなっています。
ただ、AIに関する業務となると、AIモデルの学習のあと、そのAIモデルの予測結果を、自社のサービスや業務改善に活用するフローを運用するところまでがセットとなります。ビジネス的なニーズによって、定期バッチで実行したり、モデルの予測機能をサーバアプリとして提供する場合もあります。これを行う場合、JupyterNotebookでは少々やりにくいかな、と思います。
Vertex AI Training
で、こういったニーズを解決するために、Google Cloud Platform(以降GCP)では、Vertex AIというAIに特化したプロダクトが開発されております。そのサブプロダクトであるVertex AI Trainingを用いると、GCPのマネージドな環境で、学習やハイパーパラメータチューニングを行ったり、そのモデルの予測提供するための環境も比較的簡単に作れます。
Vertex AI Trainingでは、AutoMLという、コーディングをせずとも学習ができる方法と、カスタムトレーニングという、自前でプログラムを用意して学習を実行する方法がサポートされております。今回は、Dockerコンテナを使ったカスタムトレーニングの方法を行ってみます。
今回使用する学習タスク
今回は、サンプルですので、機械学習のHelloWorldとも言える、アイリスデータの分類に挑戦してみましょう。モデルは、サポートベクターマシンによる分類器を試してみます。
(あ、ちなみに著者はあまり機械学習モデルの詳しい仕組みについては詳しくないのであしからず。。)
データ
BigQueryのiris_dataというデータセットにiris_tableというテーブルを用意しました。列名はこんな感じです。
| 列名 | 型 | 説明 |
|---|---|---|
| sepal_length___cm__ | FLOAT | がくの長さ |
| sepal_width___cm__ | FLOAT | がくの幅 |
| petal_length___cm__ | FLOAT | 花びらの長さ |
| petal_width___cm__ | FLOAT | 花びらの幅 |
| label (今回の予測対象) | INT | アヤメの種類(0, 1, 2) |
学習コードを書く
ディレクトリ配置
ディレクトリ配置は最終的に以下のようになります。
.
├── custom_training
│ ├── Dockerfile
│ ├── Pipfile # 環境構築用
│ ├── Pipfile.lock # 環境構築用
│ └── src # 学習用ソースコード
│ └── train.py
└── docker-compose.yml環境構築
まずは、custom_trainingというディレクトリを作ります。その中に、srcというフォルダを作ります。
mkdir custom_training && cd $_
mkdir srcいま、custom_trainingディレクトリにいますので、ここでpipenvによる環境構築。
pipenv install scikit-learn google-cloud-bigquery pandas clickすると、こんな感じになります。
.
└── custom_training
├── Pipfile
├── Pipfile.lock
└── srcでは、srcのなかにtrain.pyを作成して、学習コードを書きます。
(以降、GCPプロジェクト名は <YOUR_PROJECT_ID>で伏せています)
from __future__ import annotations
import os
import pickle
import re
from dataclasses import dataclass
from typing import Union
import click
from google.cloud import bigquery
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
# Vertex AI Trainingの場合は、実際に学習が実行されるGCPプロジェクトIDが
# CLOUD_ML_PROJECT_IDという環境変数に格納される
if os.getenv('CLOUD_ML_PROJECT_ID'):
client = bigquery.Client(project=os.getenv('CLOUD_ML_PROJECT_ID'))
else:
client = bigquery.Client()
@dataclass
class GCSPath():
bucket: str
key: str
@classmethod
def get_fuse_directory_path_from_gcs_uri(cls, gcs_uri) -> str:
"""
GCSのURLを受け取って、その場所をCloud Storage FUSE経由で見るためのパスを返す。
"""
gcspath = cls.get_gcspath_from_gcs_uri(gcs_uri)
return f"/gcs/{gcspath.bucket}/{gcspath.key}"
@classmethod
def get_gcspath_from_gcs_uri(cls, gcs_uri) -> GCSPath:
"""
GCSのURL表記からバケット名とキー名を抽出して、GCSPathオブジェクトにして返す
"""
pattern = "gs://(?P<bucket>[^/]+)/(?P<key>.+)"
m = re.match(pattern, gcs_uri)
if m:
bucket = m.group("bucket")
key = m.group("key")
return cls(bucket=bucket, key=key)
else:
raise ValueError(f"{pattern} is invalid GCS URI.")
def get_gcsfuse_model_save_dir() -> Union[str, None]:
"""
GCS上にモデルを保存する用のディレクトリを取得。
Vertex AI Training上で実行していない場合はNoneを返す。
Returns:
Union[str, None]:
GCS上にモデルを保存する用のディレクトリ。
Vertex AI Training上で実行していない場合はNoneを返す。
Note:
Vertex AI Trainingで実行するとき、
自動的に環境変数AIP_MODEL_DIRにモデルの保存先のGCSのURLが渡される。
"""
model_save_dir = os.getenv("AIP_MODEL_DIR")
if model_save_dir:
return GCSPath.get_fuse_directory_path_from_gcs_uri(model_save_dir)
def get_training_data():
"""学習データをDataFrameで取得する"""
df = client.query('SELECT * FROM `<YOUR_PROJECT_ID>.iris_data.iris_table`').to_dataframe()
return df
x_col = [
"sepal_length__cm_",
"sepal_width__cm_",
"petal_length__cm_",
"petal_width__cm_"
]
y_col = "label"
@click.command()
@click.option("--model-save-dir", type=str, help="学習モデルの保存先")
def train(model_save_dir: Union[str, None] = None):
"""
学習を実行し、モデルを保存する。
Args:
model_save_dir (Union[str, None], optional):
ローカル環境で実行するときは指定が必要である。
Vertex AI Trainingで実行するときは指定は不要。
"""
# モデルを作成
model = LinearSVC()
# 学習データを取得する
train_data = get_training_data()
X, y = train_data[x_col], train_data[y_col].tolist()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# いざ、学習!
model.fit(X_train, y_train)
# モデルの保存先を取得する。
# Vertex AI Trainingで学習している場合はGCS Fuseでアクセス可能なディレクトリが
# ローカル実行の場合は、引数のmodel_save_dirが使用される。
model_save_dir = get_gcsfuse_model_save_dir() or model_save_dir
if not model_save_dir:
raise ValueError("モデルの保存先が設定されていません。")
# モデルを保存する
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
model_save_path = f"{model_save_dir}/model.p"
with open(model_save_path, "wb") as fp:
pickle.dump(model, fp)
if __name__ == "__main__":
train()ためしに動かしてみます。
# BigQueryのテーブルが存在するプロジェクトをデフォルトプロジェクトにする
gcloud config set project <YOUR_PROJECT_ID>
# 学習を実行する
pipenv run python src/train.py --model-save-dir $(pwd)学習が実行されてmodel.pというファイルが生成されました。
Dockerイメージを作る
今回はカスタムコンテナを使ってVertex AI Trainingで学習しますので、Dockerイメージを作成します。
custom_training/ディレクトリ内にDockerfileを作ります。
FROM python:3.9.6
COPY ./Pipfile.lock /app/
COPY ./src /app/src
WORKDIR /app
RUN pip install pipenv
RUN pipenv sync
# ENTRYPOINTで学習実行スクリプトが開始するようにする!
ENTRYPOINT pipenv run python src/train.pydocker-compose.ymlを、custom_trainingの親ディレクトリに作ります。
services:
backend:
image: vertex-custom-training/iris_data
build:
context: ./custom_trainingビルド
docker compose buildリポジトリにプッシュ
Vertex AI Trainingから見える位置(GCP環境上か、Docker Hub)に、Dockerイメージをプッシュしましょう。
今回はGCP内のプライベートなコンテナレジストリであるGoogle Container Registry(GCR)にプッシュします。
# GCRの認証ヘルパーを設定。gcr.ioに認証できるようになる
gcloud auth configure-docker
# あとはpushする
docker tag vertex-custom-training/iris_data:latest gcr.io/<YOUR_PROJECT_ID>/vertex-custom-training/iris_data:latest
docker push gcr.io/<YOUR_PROJECT_ID>/vertex-custom-training/iris_data:latestVertex AI Trainingで実行する
手元環境用に、google-cloud-aiplatformをインストールします。
pipenv install --dev google-cloud-aiplatformcustom_training内に、submit-training-job.pyを作成します。
from google.cloud import aiplatform
display_name = "verify-vertex-ai-training-iris"
# さっき作ったDockerイメージのURL
image_uri = "gcr.io/<YOUR_PROJECT_ID>/vertex-custom-training/iris_data:latest"
# ステージング(モデルを置いたりチェックポイントをおくところ)用のバケットを1つ作る
staging_bucket = "gs://<YOUR_BUCKET_NAME>/verify-vertex-ai-training-iris/staging"
custom_job = aiplatform.CustomContainerTrainingJob(
display_name=display_name,
container_uri=image_uri,
staging_bucket=staging_bucket
)
custom_job.run(
machine_type="e2-standard-4"
)このスクリプトを実行すると、Vertex AI Training上で学習が実行できます。
pipenv run submit-training-job.py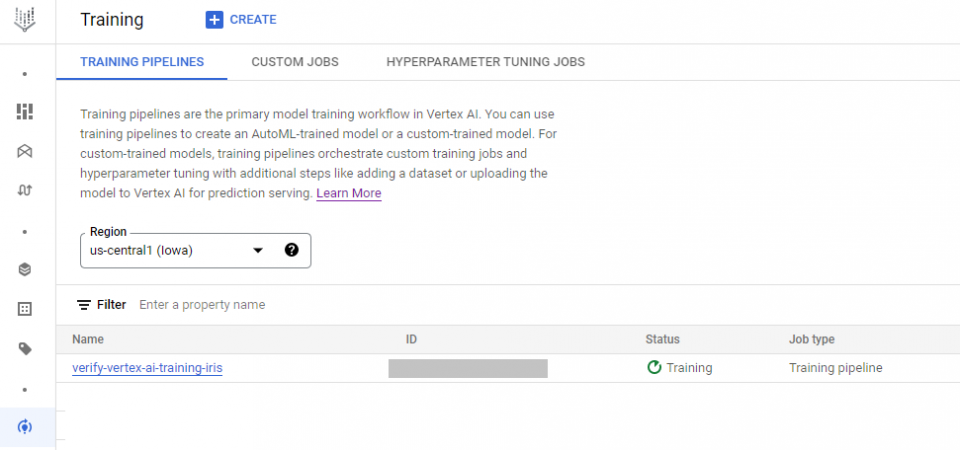
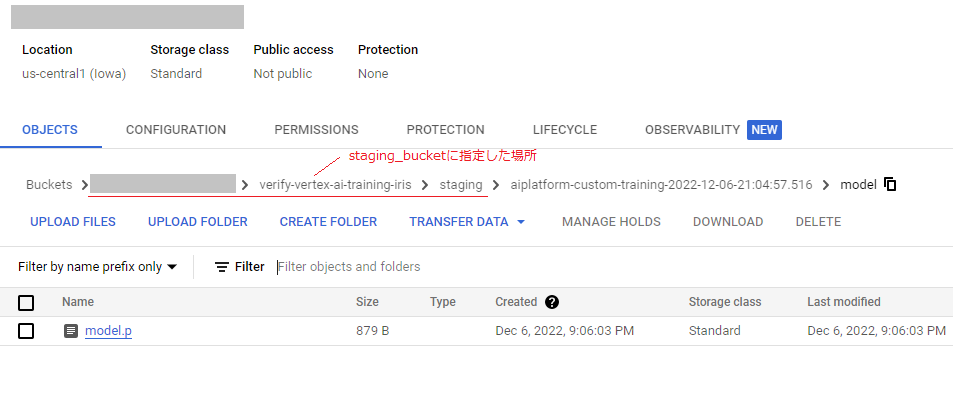
学習が完了すると、submit-training-job.py内で変数staging_bucketに設定したGCSの場所に、モデルが保存されていると思います。
感想とまとめ
今回は普通にモデル学習のみを行う部分を作ってみました。
アイリスデータのような小さなデータであれば、デスクトップ上でも実行できてしまいますが、実際もっと大きなデータを扱う場合は、もっと大きな計算リソースが必要になる場合もあります。
大きな計算リソースでNotebookを手動で実行することもできますが、Vertex AI Trainingのようなマネージド学習環境を使うと、学習が終わると使われた計算リソースが勝手に落ちるので、安心だしコスト効率もいいと思います。
また、すごーく長くなりそうなので今回は触れなかったのですが、分散処理やハイパーパラメータチューニングも、コスト効率よく実行できたり、予測サービスとして提供する場合のコンテナも簡単に作れるので、機会があればやってみたいと思います。
※サムネ画像で利用しているロゴはVertex AI Trainingより引用
※本記事は2022年12月時点の情報です。

