




エンジニアブログの更新分をGmailに通知してみた

この記事の目次
概要
マイナビエンジニアブログの記事をスクレイピングして、更新される度に通知が飛ぶプログラムをGASのライブラリであるCheerioで作りたい!!
前提
マイナビエンジニアブログを自動通知したいと思うときがきっと来るはず。。。
そんな時に役立つのが、今回紹介するCheerioを使ったスクレイピングの技術です!!
流れとしては、GASとスプレッドシートを紐づけてGASでURLをスクレイピングした後に、スプレッドシートのURLと照合して、もしURLが一致していたら、スプレッドシートに書き込みとGmail通知をしないようにします。どのURLとも一致しなかったら、スクレイピングしてスプレッドシートに書き込みします。書き込んだあとは、Gmailに通知を飛ばす処理を書く感じ。。。
下ごしらえ
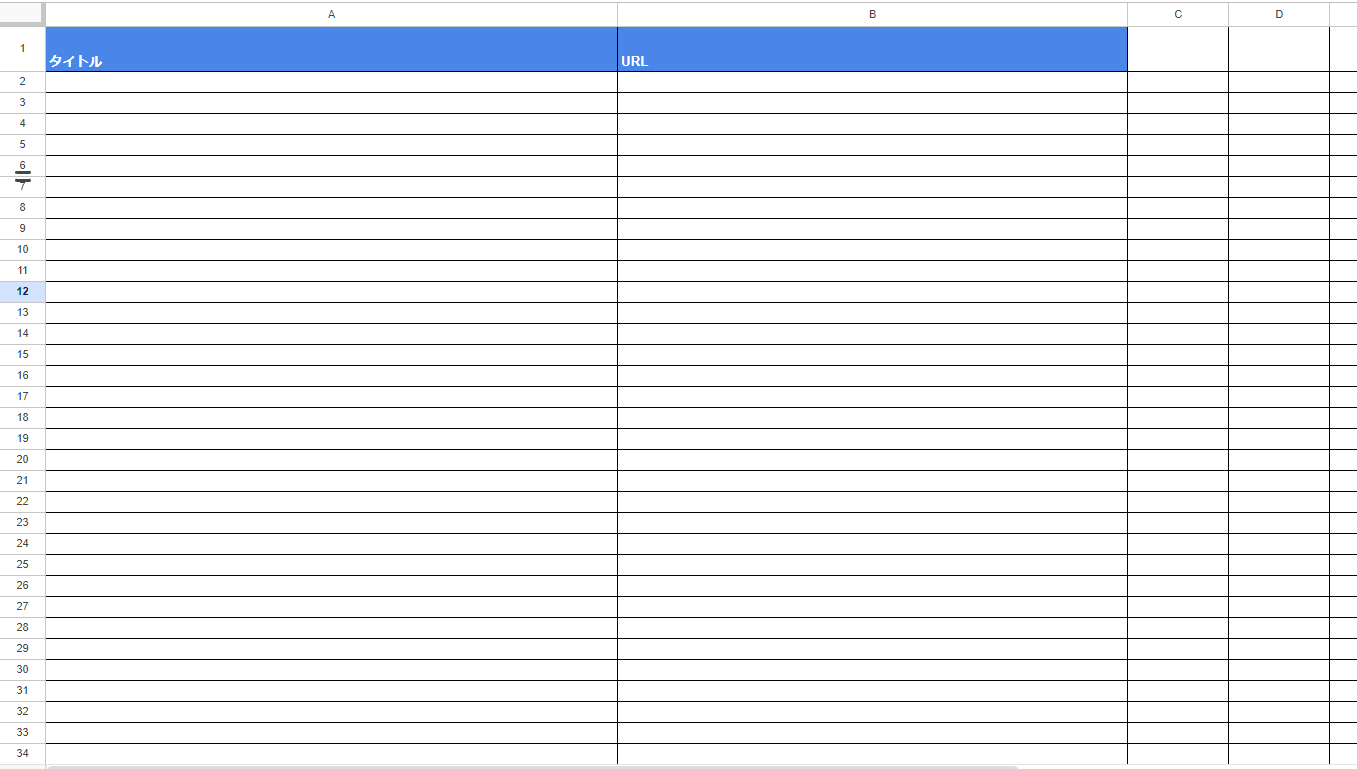
①Google Drive上にスプレッドシートを作成します。スプレッドシートのヘッダー及び、UIは以下の図のようにします!
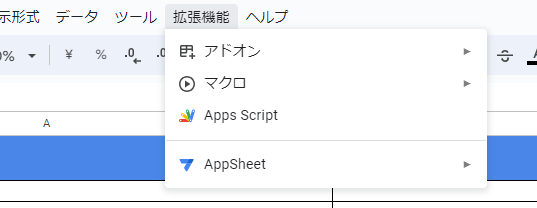
 ②作成したスプレッドシートの拡張機能から、Google Apps Script(以降、GASと表記)を選択します。
②作成したスプレッドシートの拡張機能から、Google Apps Script(以降、GASと表記)を選択します。
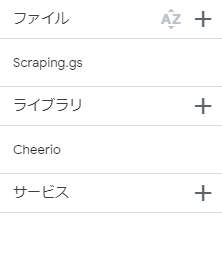
③GASのライブラリタブの「+」ボタンを押し、CheerioのIDをコピペしましょう!
- CheerioのID
1ReeQ6WO8kKNxoaA_O0XEQ589cIrRvEBA9qcWpNqdOP17i47u6N9M5Xh0- これをGASのライブラリのところにコピペしましょう!
- Cheerioとは、簡単に説明するとHTML要素を受け取り、DOM操作的なことをするためのライブラリです!
④マイナビエンジニアブログ一覧のURLです。どこかにメモをしておきましょう!ホームページ上で「F12キー」を押すと、開発者画面になります。
https://engineerblog.mynavi.jp/posts/本題
関数定義
Webスクレイピングには、HTML要素が必要なので、まず、URLからHTML要素を取ってくる処理を書きます。
function scraping() {
let resultList = [];
const html = UrlFetchApp.fetch("https://engineerblog.mynavi.jp/posts/").getContentText();
const cheerio = Cheerio.load(html);
}分解すると、以下のようになります。
let resultList = [];これは、最終的なスクレイピング結果を格納するリストです。scraping関数のうち、最も上位階層に書きます。
UrlFetchApp.fetch("各サイトのURL").getContentText();これで、そのWebページ全てのHTML要素を取得でき、
Cheerio.load("HTML要素");こちらで、Cheerioによって、HTML要素を分析するための準備ができました。
Cheerioの使い方
ここから先のCheerioの使い方としては、
cheerio('クラス.クラス名').each(function(i, elem) {
cheerio(elem).text();
})上記のコードで、タグで囲まれたテキストを取得でき、
cheerio('クラス.クラス名').each(function(i, elem) {
cheerio(elem).attr('タグ名');
})こちらで、タグの中にある要素の値を取得できます。
実際にCheerioを使う
// ブログのタイトル一覧を取得
let titleList = [];
cheerio('div.article-info h3.article-list-title-h3').each((i, elem) => {
titleList.push(cheerio(elem).text().toString());
})
// ブログの各URLを取得
let urlList = [];
cheerio('div.archive-contents div.list-content ul li.article-list-li-type5 a').each((i, elem) => {
let url = "https://engineerblog.mynavi.jp" + cheerio(elem).attr('href').toString();
if (!(url.includes('tag'))) {
urlList.push(url);
}
})上記のコードで、それぞれのブログのタイトルとURLが取得できました。
詳しく見ていきましょう!
let titleList = [];タイトルを格納するリストを作ります。
let titleList = [];
cheerio('div.article-info h3.article-list-title-h3').each((i, elem) => {
titleList.push(cheerio(elem).text().toString());
})このコードで、ブログのタイトルが取得できています!
'div.article-info h3.article-list-title-h3'cheerio()の中に、このようにありますが、記法はCSSと似ていて、
'タグの名前.クラス名 タグの名前#ID名'これでタグで囲まれた要素を取得できます。ここで「.」は、次に続く文字列がクラス名であることを表しています。
- 「.」= クラス
- 「#」= ID
左から右にかけてより詳細なタグへと向かうように書きます。タグとの間は空白を空けましょう!
次に、Cheerioで解析したHTML要素を一つずつ取り出します。
.each((i, elem) => {
})eachの第2引数に解析結果が格納されています。
cheerio(elem)解析結果は、これで取り出すことができました!また、cheerio()は、text()、attr()を持つことができます。
- cheerio().text() → タグで囲まれた文字列を取得
- cheerio().attr() → タグ内のクラスや、hrefの値を取得
今回は、h3タグで囲まれたタイトルを取得したいため、text()を使います。
titlelist.push()titleListのリストに、取得したタイトルを追加します。
以上の作業で、タイトルが取得できます。
次に、URLを取得するコードを見てみましょう!
<a class="hover-thumb_title-mynavi_life" href="/mynavi_life/mynavi_sys_newoffice/"></a>URLは、このように、aタグの中にあります。これを取得するには、前述のようにattr()で取得します。
cheerio(elem).attr('href')これで、aタグの中にあるhref情報を取得できます。
しかし、実際のHTMLを見ると、このさらに下の階層にaタグとhref情報が存在します。この下の階層のhrefは取得したくないので、href情報の値で、絞り込みを行う必要があります。
今回必要なURLは、tagという文字列が入っていないURLです。
let url = "https://engineerblog.mynavi.jp" + cheerio(elem).attr('href').toString();
if (!(url.includes('tag'))) {
urlList.push(url);
}このように書くことで、tagがついていないときにurlListに追加する処理が実現できます。
以上のコードで、ブログのタイトルとURLを取得することができました。
スプレッドシートに書き込み
ここからは、スクレイピングした情報をスプレッドシートに書き込みを行います。
その前に、今回のスクレイピングは同じものをスクレイピングしないようにしたいので、URLを照合する処理を書きましょう。
const spreadSheet = SpreadsheetApp.openById(<スプレッドシートID>);
const sheet = spreadSheet.getSheetByName(<シート名>);
const urlValues = sheet.getRange(2, 2, sheet.getLastRow(), 1).getValues();
//多次元配列を一次元配列に変換
const urlValuesFlat = urlValues.flat();URL照合には、URLのみを取得すれば良いので、(2, 2, シートの最後の行, 1)が範囲となります。
flat関数は、多次元配列を一次元配列に直す関数です。getValues()で取得した値は、二次元配列のため、一次元配列に直す必要があります。
このコードは、resultListを定義した上位階層の部分に書きます。
次に、スプレッドシートに書き込みを行うには、二重リストである必要があります。
if (titleList.length == urlList.length) {
for (let j=0; j<urlList.length; j++) {
if ( !(urlValuesFlat.includes(urlList[j])) ) {
resultList.push([titleList[j], urlList[j]]);
}
}
} else {
throw new Error("タイトルとURLの数が一致しません");
}resultListを用意して、その中に、リストを埋め込むことで、resultListは二重リストになります。
forループで数字を回すことで、タイトルとURLがそれぞれ入っているリストのIndexを回すことができます。
if ( !(urlValuesFlat.includes(urlList[j])) )この部分は、スプレッドシートにもともとあるURLとスクレイピングしてきたURLが被っていないかを照合しています。
被っていなかったら、resultListに、タイトルとURLをpushします。
if (titleList.length == urlList.length) {
} else {
throw new Error("タイトルとURLの数が一致しません");
}この部分は、タイトルとURLの数が一致していたらresultListにpushする処理です。
もし数が合わないと、違うURLを取得していることになるため、エラーにしましょう。
やっとスプレッドシートに書き込む準備が整いました!!
// スプレッドシートに書き込み
if (resultList.length > 0) {
sheet.getRange(sheet.getLastRow()+1, 1, resultList.length, 2).setValues(resultList);
}resultListに値が入っているときに、書き込み処理を行います。
書き込む行は、前にスクレイピングしたブログの下に入れるので、スプレッドシートに値が入っている最後の行+1が、書き込みを始める行になります。書き込む行数は、リストの値の数の分だけです。
そのため、(最後の行+1, 1, リストの長さ, 2)となっています。
複数ページのfetch
エンジニアブログは、もちろん1ページでは終わっておらず、複数ページにまたがります。ページをループさせ、それぞれのページでもURLfetchを行っていきましょう。
for (let i=0; true; i++) {
try {
const html = UrlFetchApp.fetch(
`https://engineerblog.mynavi.jp/posts/page/${i}/`).getContentText();
const cheerio = Cheerio.load(html);
/**
* スクレイピング処理
*/
// 要素が取得できなかったら、ブログは存在しないのでbreak
if (titleList == "") {
break;
}
/**
* スクレイピング処理
*/
} catch(e) {
console.log(e.message);
break;
}
}
for (let i=0; true; i++)まず、上のコードでページ番号をループさせます。
`https://engineerblog.mynavi.jp/posts/page/${i}/`このように埋め込むことで、各ページのfetchが可能になります。
このままだと、無限ループになるため、タイトルが取得できなくなったらbreakすることも忘れずに!!
if (titleList == "") {
break;
}念のため、エラーが発生した際もbreakしましょう!
catch(e) {
console.log(e.message);
break;
}ちなみに、トライキャッチとは、簡単に言うとエラーが発生しない間はトライの処理を行い、エラー発生でキャッチの処理を行うことを指します。
ここまでで、スクレイピングの処理が完了しました!!ここまでのコードをまとめると、次のようになります!
function scraping() {
let resultList = [];
const spreadSheet = SpreadsheetApp.openById("1CSRh2KnFP33wb1QPigBCxw7xD5c8EvgmBJzXAts7Ias");
const sheet = spreadSheet.getSheetByName("スクレイピング結果");
const urlValues = sheet.getRange(2, 2, sheet.getLastRow(), 1).getValues();
for (let i=1; true; i++) {
try {
const html = UrlFetchApp.fetch(`https://engineerblog.mynavi.jp/posts/page/${i}/`).getContentText();
const cheerio = Cheerio.load(html);
//多次元配列を一次元配列に変換
const urlValuesFlat = urlValues.flat();
// ブログのタイトル一覧を取得
let titleList = [];
cheerio('div.article-info h3.article-list-title-h3').each((i, elem) => {
titleList.push(cheerio(elem).text().toString());
})
// 要素が取得できなかったら、ブログは存在しないのでbreak
if (titleList == "") {
break;
}
// ブログの各URLを取得
let urlList = [];
cheerio('div.archive-contents div.list-content ul li.article-list-li-type5 a').each((i, elem) => {
let url = "https://engineerblog.mynavi.jp" + cheerio(elem).attr('href').toString();
if (!(url.includes('tag'))) {
urlList.push(url);
}
})
if (titleList.length == urlList.length) {
for (let j=0; j<urlList.length; j++) {
if ( !(urlValuesFlat.includes(urlList[j])) ) {
resultList.push([titleList[j], urlList[j]]);
}
}
} else {
throw new Error("タイトルとURLの数が一致しません");
}
} catch(e) {
console.log(e.message);
break;
}
}
// スプレッドシートに書き込み
if (resultList.length > 0) {
sheet.getRange(sheet.getLastRow()+1, 1, resultList.length, 2).setValues(resultList);
}
}メール送信
あとは、メール送信のコードを書いて終了です!!
function sendGmail(resultList) {
const toMail = '<送信先メールアドレス>';
const subject = '【自動送信】エンジニアブログの更新';
const options = { from: '<送信元メールアドレス>' };
let bodyList = [];
for (let result of resultList) {
let eachBody = `${result[0]}(${result[1]})`;
bodyList.push(eachBody);
}
const joinBody = bodyList.join('\n');
const body = `以下のエンジニアブログが更新されました!\n\n${joinBody}`;
GmailApp.sendEmail(toMail, subject, body, options)
}詳しく見ると、以下のようになります!
const toMail = '<送信先メールアドレス>';
const subject = '【自動送信】エンジニアブログの更新';
const options = { from: '<送信元メールアドレス>' };これは、メールの送信先、題名、送信元を指定しています。
let bodyList = [];
for (let result of resultList) {
let eachBody = `${result[0]}(${result[1]})`;
bodyList.push(eachBody);
}
const joinBody = bodyList.join('\n');
const body = `以下のエンジニアブログが更新されました!\n\n${joinBody}`;これは、本文に更新されたブログのタイトルとURLを載せているコードです。
一旦、一次元リストにまとめてから、それをjoin関数を用いて、改行区切りで文字列に変換しています。
変数bodyに本文を埋め込んで、
GmailApp.sendEmail(toMail, subject, body, options);これで送信完了!!
あとは、このメール送信のタイミングが、resultListを書き込むときにすれば、まとめて更新分のブログを送信できます。
/**
* メール送信
* スプレッドシート書き込み
*/
if (resultList.length > 0) {
sendGmail(resultList);
sheet.getRange(sheet.getLastRow()+1, 1, resultList.length, 2).setValues(resultList);
}scraping関数の中の、このif文の中に埋め込みましょう!
トリガー設定
最後に、完全自動実行を実現てみましょう!
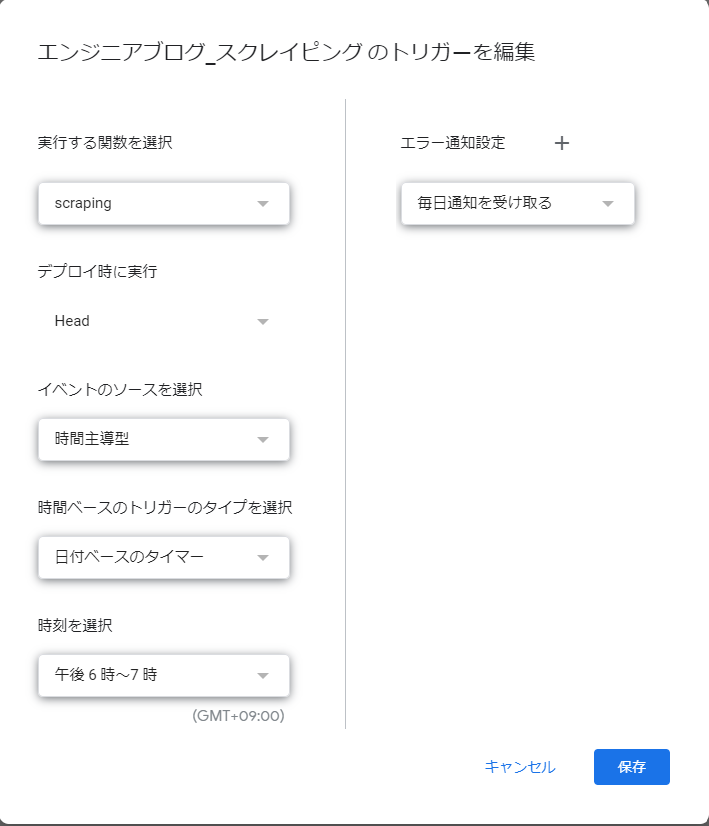
GASにはトリガーが設定できます。今回は、毎日18:00になるとスクレイピング処理するトリガーをセットします。
- メニューから、「トリガー」を選択します。
- 右下にある「+トリガーを追加」ボタンを押します。
- 「実行する関数を選択」をscraping、「イベントのソースを選択」を「時間主導型」、「時間ベースのトリガーのタイプを選択」を「日付ベースのタイマー」、「時刻を選択」を「午後6時~7時」にします。
- あとは既定の値で、「保存」ボタンを押します。

上の図のようになってたらOK!!
完成
▼完成コード
function scraping() {
let resultList = [];
const spreadSheet = SpreadsheetApp.openById("1CSRh2KnFP33wb1QPigBCxw7xD5c8EvgmBJzXAts7Ias");
const sheet = spreadSheet.getSheetByName("スクレイピング結果");
const urlValues = sheet.getRange(2, 2, sheet.getLastRow(), 1).getValues();
//多次元配列を一次元配列に変換
const urlValuesFlat = urlValues.flat();
for (let i=1; true; i++) {
try {
const html = UrlFetchApp.fetch(`https://engineerblog.mynavi.jp/posts/page/${i}/`).getContentText();
const cheerio = Cheerio.load(html);
// ブログのタイトル一覧を取得
let titleList = [];
cheerio('div.article-info h3.article-list-title-h3').each((i, elem) => {
titleList.push(cheerio(elem).text().toString());
})
// 要素が取得できなかったら、ブログは存在しないのでbreak
if (titleList == "") {
break;
}
// ブログの各URLを取得
let urlList = [];
cheerio('div.archive-contents div.list-content ul li.article-list-li-type5 a').each((i, elem) => {
let url = "https://engineerblog.mynavi.jp" + cheerio(elem).attr('href').toString();
if (!(url.includes('tag'))) {
urlList.push(url);
}
})
if (titleList.length == urlList.length) {
for (let j=0; j<urlList.length; j++) {
if ( !(urlValuesFlat.includes(urlList[j])) ) {
resultList.push([titleList[j], urlList[j]]);
}
}
} else {
throw new Error("タイトルとURLの数が一致しません");
}
} catch(e) {
console.log(e.message);
break;
}
}
/**
* メール送信
* スプレッドシート書き込み
*/
if (resultList.length > 0) {
sendGmail(resultList);
sheet.getRange(sheet.getLastRow()+1, 1, resultList.length, 2).setValues(resultList);
}
}
function sendGmail(resultList) {
const toMail = '<送信先メールアドレス>';
const subject = '【自動送信】エンジニアブログの更新';
const options = { from: '<送信元メールアドレス>' };
let bodyList = [];
for (let result of resultList) {
let eachBody = `${result[0]}(${result[1]})`;
bodyList.push(eachBody);
}
const joinBody = bodyList.join('\n');
const body = `以下のエンジニアブログが更新されました!\n\n${joinBody}`;
GmailApp.sendEmail(toMail, subject, body, options);
}これで完成です!!scraping関数を実行すると、更新分だけ、スプレッドシートに書き込みを行い、メール通知が来ます。
初回のスクレイピング処理は、すべて取ってくるため、メール通知には、全てのエンジニアブログが来ます。
所感
Cheerioを使うと、GASでも比較的簡単にスクレイピングができるんです!私自身、Parserというライブラリも試しましたが、要素を取り出すときに苦労しました。
結果的にはCheerioで良かったと思っています!
業務では、似たようなスクレイピングを行うことがありますが、そのときもCheerioを使ってスクレイピングすることが多いです。
今回紹介したスクレイピングで、ブログの自動通知を行うというものは、業務自動化の一種なので、広義の意味でRPAに該当します!ぜひ、この記事を見ている方々は試してみてほしいです!!
※本記事は2023年12月時点の情報です。

