




DeepDreamによる悪夢のような画像変換

この記事の目次
何の記事?
AIで画像に悪夢のような変換を施す手法を紹介します!
例)集合体が苦手な方は閲覧注意です…
※画像はtensorflowより引用

↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓

この手法を
- TensorFlowのチュートリアル通りに実装する際の流れの解説とTips
- 実際に試した例
を紹介する記事です!
何に使うの?
画像認識でDNN(Deep Neural Network)がちゃんと学習できているのかを可視化できる
- 深層学習ではモデルの予測が何を根拠に判断されているかが分からないという問題があり、その解決方法の一つ
- 同様の可視化手法で有名なのはCAM(後述)
コンピュータービジョンの表現方法としての可能性
- 実際にプロのアーティストのミュージックビデオで使用されている
- Doing It for the Money (Foster The People)
◦ 0:37~をご覧ください
説明
概要
DeepDreamとは
Alexander Mordvintsevによって作成されたコンピュータービジョンプログラムです。
画像の分類をするために学習した特徴を、逆に画像に足して出力することで悪夢のような変換をしています。
TensorFlowのチュートリアル通りに実装すれば任意の画像で変換可能。
チュートリアルではimagenet(物体認識ソフトウェアの研究で用いるために設計された大規模な画像データベース)で学習した機械学習モデルを使用しています。
やり方
チュートリアルを参考に、好きな画像でやってみましょう!!
基本的な流れを紹介し、ちょっとずつTipsも加えます。
- 画像を用意
・変換前の画像を用意します。
・Tips:画像があまり大きいと時間がかかることがあります! - 特徴抽出モデルを用意
・チュートリアルではInceptionV3を使用しています。
・InceptionV3は、GoogLeNet (Inception v1) を改良したモデルです。tensorflowではImageNetによる事前学習済みモデルが用意されています。
・Tips: InceptionV3でなくとも任意の事前学習済みモデルを使用できます!KerasのAPIには多くの事前学習済みモデルがあるため、モデル変更の際はそちらを試してみるといいかもしれないです! また、事前学習済みモデルを任意のデータセットで転移学習したものを使う ことにより、任意の悪夢風変換を行うこともできます! このあとの章で自分の顔で転移学習したものを使った例を載せています。 - 損失を計算
・チュートリアルの損失計算部分では、選択した各レイヤーのすべての平均を取り、全レイヤーの平均値を合計したものを返しています。 - 勾配上昇方
・普通は勾配降下法で損失を小さくしていきますが、DeepDreamでは入力画像に対して計算した勾配を元の画像に追加する勾配上昇方で変換を行っています。
その他補足
- チュートリアル内で選択した画像の変換に使うレイヤーは、選択したレイヤーを最終層としたモデルを作成するのにつかわれています。つまりInceptionV3を指定レイヤーの部分で区切ったモデルを使って勾配の抽出を行っている感じです。
↓レイヤーを選択している部分↓
# Maximize the activations of these layers
names = ['mixed3', 'mixed5']
layers = [base_model.get_layer(name).output for name in names]- 基本は変換したい画像に対して勾配を計算して元の画像に足すだけですが、 勾配を小さくしたやつを何回も足すようにするとイイ感じになります!
img = img + gradients*step_size- 入力画像を拡縮してちょとずつ勾配を足してもイイ感じになります(Octaveという手法)
def octave(original_img):
OCTAVE_SCALE = 1.30
img = tf.constant(np.array(original_img))
base_shape = tf.shape(img)[:-1]
float_base_shape = tf.cast(base_shape, tf.float32)
for n in range(-2, 3):
new_shape = tf.cast(float_base_shape*(OCTAVE_SCALE**n), tf.int32)
img = tf.image.resize(img, new_shape).numpy()
img = run_deep_dream_simple(img=img, steps=50, step_size=0.01)
img = tf.image.resize(img, base_shape)
img = tf.image.convert_image_dtype(img/255.0, dtype=tf.uint8)
return imgCAMとの違い
同様の画像分類モデル可視化手法であるCAM(Class Actiovation Mapping)では、勾配を取得し分類スコアに最も影響を与える入力画像の部分を識別します。
CAMの一般化手法であるGrad-CAMでの出力例
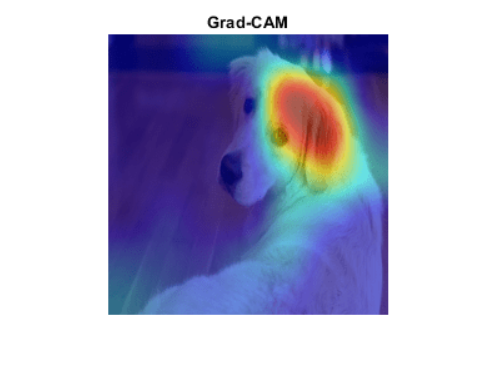
このような出力をするにあたり、CAMでは重要度をヒートマップで表した画像を新たに作成し、元の画像の上に薄く重ねます。
それに対してDeepDreamでは入力画像に対して計算した勾配を、小さく薄めて元の画像に直接足しています。
転移学習で任意の変換をしてみた
ざっくりとした流れ
顔写真をたくさんあつめてデータセットを作る
↓自分の画像↓

tensorflowの転移学習チュートリアルに従ってInceptionV3を転移学習しました。(犬と猫のデータセットを自前のデータセットに置き換えるだけです)
転移学習後、InceptionV3のレイヤーConv2dの5と6を選択してDeepDream
↓選択レイヤーを出力にした勾配計算用のモデル図↓

結果
若干髪の毛などの特徴で変換が行われている、、、?

おわりに
以上、悪夢のような画像変換を行うAI手法「DeepDream」の紹介でした。
手法自体は少し昔のものですが、内容はインパクトがあって面白いと思い紹介させていただきました。
昨今流行っている画像生成AIよりも仕組みは簡単だと思うので、この記事を見て興味を持った方はぜひトライしてみてください。
おまけ・勾配を小さくしないでそのまま入力画像に足した場合のDeepDream
Stepsizeを0.1にするとこんな感じでした。

ノイズに近いですね。ちょっとゴーギャンっぽい?
※本記事は2023年12月時点の情報です。

