




普段AWS触ってない人間がLambdaとAthenaでなんか地味に苦労した話

この記事の目次
はじめに
この記事では、AWSの資格であるSAAを取得したもののそこまでAWSを触っていなかったAWS初心者が、業務にそこまで影響がない範囲内でAWSでなんか作ってみようと思い立ち、学習目的半分で試行錯誤した結果触ってみて初めて知った苦労などを記載しています。
AWSを日常的に触っている人にとっては知ってる内容かもしれませんが(もしくは触ったことなくても別に躓かないかもしれない)、AWS初心者でかつ日常的にコードも書かない、データベースの扱いにも全く慣れていない人間としては苦労したポイントがいくつかありました。
「そんなんも知らんのかプークスクス」と笑わずに大目に見てくれると嬉しいです!!
目指したもの
Slackのフリープランでも90日前のメッセージを遡れるシステム
きっかけ
2022年9月1日からのアップデートで、フリープランだとSlackで共有されたメッセージやファイルは90日経過後に閲覧できなくなりました。
社内のコミュニケーションにメイン使っているエンタープライズプランのものとは別に、アラート発報用のワークスペースをフリープランで契約しており、Slackでの契約プランは変更せずなんとか90日経過後でもメッセージが遡れるようにできないかという思いから作ってみました。
作ったシステムの概要
簡易構成図
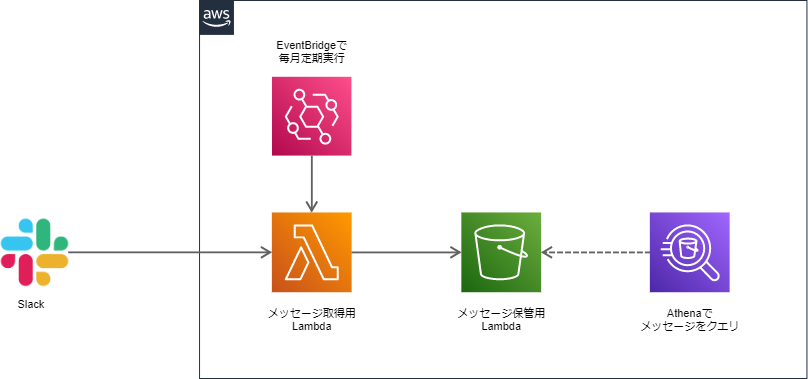
大体の仕組み
- EventBridgeで毎月1回Lambda実行し、Slackに全メッセージを取りに行く
- Lambdaで取得したメッセージのファイル形式を変換し、S3に保管する
- Athenaで取得したい要件に合わせてクエリを投げる
- チャンネル名、日付、etc…
90日経過で消えるので月一じゃなくてもいいのですが、万が一コケた時に気付くのが遅れないよう月一実行にしました。
また、通常ログの保存や検索にはElasticSearchを使うのがベストプラクティスかと思いますが、今回は以下を理由にAthenaを採用しました。
- クエリごとの課金となるので比較的コストを抑えられる
- システムの使用頻度的に、正直そこまでクエリ投げないであろう想定
- サーバレスなのでインフラの面倒を見る必要がない
- クエリできるデータ形式が豊富である
- 正直に言うとAthenaを良い感じに使ってみたかった(本音)
個人的に苦労した実装に対しての感想
何度でも言いますが、大目に見てください…
Athenaでクエリできるファイル形式がなんか思ってたのと違ったんだけど
Athenaでクエリできるファイル形式としてcsv、parquet、jsonなどが公式で紹介されています。
AWSユーザーガイド : サポートされる SerDes とデータ形式
今回はSlackの検索結果がJSON形式で簡単に取得できるためJSON形式を選びましたが、 厳密には単なるJSONではない ことにすぐ気付けず、少し悩んでいた時間がありました。
公式ドキュメントには、サポートされるJSON形式について以下のように説明されています。
JSON (JavaScript Object Notation) JSON データでは、各行がデータレコードを表します。 各レコードは属性/値のペアと配列で構成され、それぞれがカンマで区切られます。
つまり、複数レコードの場合は、
[
{"key1": "value1", "key2":"value2"},
{"key1": "value1", "key2":"value2"},
{"key1": "value1", "key2":"value2"}
]ではなく、
{"key1": "value1", "key2":"value2"}
{"key1": "value1", "key2":"value2"}
{"key1": "value1", "key2":"value2"}としてファイル出力する必要があり、この形式はJSON Linesと言われている書式となります。
つまり、取得したJSON形式のファイルを更にJSON Lines形式へ変換する必要があります。
JSON Lines形式を扱う方法はpandasなどいくつかありますが、今回はjsonlinesのライブラリを使って実装しました。
import jsonlines
content = [
{"key1": "value1", "key2":"value2"},
{"key1": "value1", "key2":"value2"},
{"key1": "value1", "key2":"value2"}
]
path = "/your/path/to/store/file.json"
with jsonlines.open(path, mode="w") as writer:
writer.write_all(contents)JSON形式と言われると、通常はファイル全体がJSONオブジェクトとして解釈可能である必要と思い込んでいました。
自分としては正しいJSON形式で出力しているにも関わらず、Athenaでクエリが失敗するため、何故…となり、地味に調査に時間がかかったポイントでした。
Athenaを使ったことがある方なら知っていることかもしれませんが、Athena初体験だったので印象に残っています。
S3にファイルをアップロードする際の暗号化の仕方ってマネージメントコンソール使わない時どうすればいいの?
S3にファイルをアップロードする際、何らかの暗号化を施すことが多いかと思います。
マネージメントコンソール上で操作する際は画面上で選択すればよさそうですが、API上でどう指定すればいいのか知らなかったため苦労しました。
API上では、呼び出す際に指定する引数に以下のように ExtraArgs内で指定するとSSE-S3により暗号化され、アップロードできます。
import boto3
bucket_name = "bucket name"
object_name = "object name"
s3 = boto3.resource("s3")
s3.Object(bucket_name, object_name).upload(
ExtraArgs={
"ServerSideEncryption": "AES256"
}
)ちなみに、ここで AES256をaws:kmsに置き換えると、AWS KMSと連携して別のキーで暗号化できるため、ここは要件によって変えればよさそうだなと思っています。
Athenaのスキーマ作成の手間が思ってたより多くて諦めそうだった
AthenaでJSONをクエリするためには、テーブルを作成する必要がありましたが、通常のSQLとスキーマの定義方法が異なります。
特に、
- ネストしたJSONをテーブル上で定義する
- SQLとのデータ型の違い
- 暗号化・GZIP圧縮した元データの参照方法
は、テーブル作成において何度か詰まって確認したポイントです。
ただでさえデータベース苦手なので、何言ってんだこりゃあ…となりました。
以下は実際に作成したスキーマです。
CREATE DATABASE IF NOT EXISTS your_database
LOCATION 's3://your-bucket/';
CREATE EXTERNAL TABLE IF NOT EXISTS `your_database`.`your_table` (
iid string,
team string,
channel struct<
id: string,
name: string>,
type string,
user string,
username string,
ts timestamp,
text string,
permalink string
) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'ignore.malformed.json' = 'FALSE',
'dots.in.keys' = 'FALSE',
'case.insensitive' = 'TRUE',
'mapping' = 'TRUE'
)
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://your-bucket/'
TBLPROPERTIES (
'has_encrypted_data' = 'true',
'classification' = 'json',
'write.compression' = 'GZIP',
'classification' = 'json'
);テーブル定義内のchannelのカラムで、このキーはJSON上ではネストしたオブジェクトとして表現されていました。
このようなデータはAthenaでは struct(構造体) と表現されています。
AWSユーザーガイド : Amazon Athena のデータ型
今回は、channelのオブジェクトの内一部が必要だったため、構造体として以下のように定義しました。
channel struct<
id: string,
name: string>,また、timestampにはJSON上では小数点付きのUNIXエポック時間が格納されていますが、このままでは不便なのでこのカラムには timestamp型 を設定しました。
これにより、日時でクエリしたい場合は、
SELECT * FROM "your_database"."your_table" WHERE ts > timestamp '2022-10-25 00:00:00'のように、日付文字列で直観的に検索が可能となります。
さらに、今回は参照するオブジェクトをSSE-S3による暗号化とGZIP圧縮しています。
そのため、テーブル定義のTBLPROPERTIESセクションにて以下のように指定しました。
TBLPROPERTIES (
'has_encrypted_data' = 'true',
'classification' = 'json',
'write.compression' = 'GZIP',
'classification' = 'json'
);これで、元データが圧縮かつ暗号化されたデータでもクエリしてくれるようになります。
ちなみにですが、今回はAthena検索時のS3のパーティションは分けずに進めています。
ファイルは月毎に生成される想定なので、クエリを投げる際は全文検索のようになり、パーティション分けても分けなくてもこのシステムの構成上変わりはないです。
しかし、ファイル保存量が多かったり、クエリを投げる際の条件でもっと絞れるようでしたら、パーティションを分けた方が費用面でとてもよいです。
現在はこのシステムを作ったばかりなのでファイル量が多くなく、クエリ回数が少なく済んでいますが、今後のことを考えるとファイル保存方法の仕様を見直したいと思います。
EventBridge「cron式です(大嘘)」
EventBridgeで毎月実行のスケジュール登録する際、普通のcron表記と書き方が違ったのでおや…と思った部分になります。
今回はマネージメントコンソール上でやってたので時間がかかったとかよくわからなかったとかではないのですが、マネージメントコンソールを使わず設定してたら詰まったかもしれないなと思います。
例えば、毎月6日の7:00に実行する、というのを書こうと思うと
0 7 6 * *となると思いますが、AWSのドキュメントでは以下のように記載されています。
? (疑問符) ワイルドカードは任意を意味します。 [日] フィールドに 7 と入力し、7 日が何曜日であってもかまわない場合、[曜日] フィールドに ? を入力できます。
さらに、最後尾には年も指定することになります。
今回は下記のようになります。
0 7 6 * ? *実際の設定画面はこちら↓
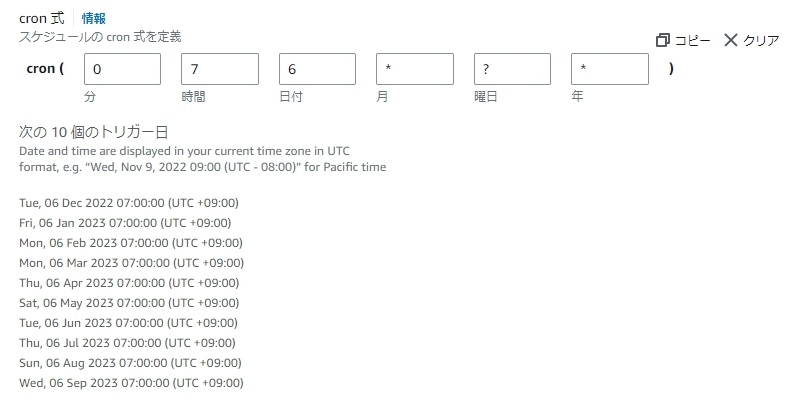
マネージメントコンソールに従って設定していくとそこまで時間のかかる躓きポイントではないのですが、気になったのでいろいろ調べてみると下記の記事を見つけました。
記法に注意が必要そうな場面も出てきそう、ということで覚えておこうと思います。
参考 : クラスメソッド AWSでのCron表記でハマったので仕様を確認しておく
なんやかんやあってできあがったもの
こんな感じのものができました。
例えば、チャンネル名を指定して、指定のチャンネル内で交わされた全メッセージを見てみたいと思います。
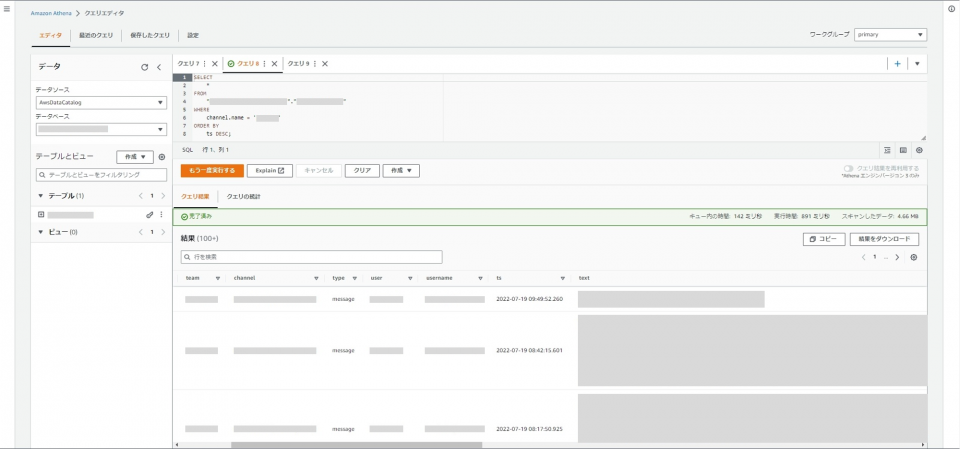
見せられる部分が少なくて恐縮ですが…一応当初の想定通り、90日以上前のメッセージも取得できています。やったね!
おわりに
今回はAWSの学習目的の元、Slackメッセージを取得しておいていつでもメッセージを見ることができるシステムを作りました。とりあえず動いてはいます。動いてるってすばらしいね。
ここまで書いておいてすごい今更なのですが、メッセージ数によっては有料プランに変更した方が結果的に安く済むかもし楽じゃない?、みたいな見方ももちろんあります!!ただ、今回のことを通じて1つ勉強になったので、良い機会だったなと思います。
まだまだ改修すべき点や設計を見直したい箇所、考慮漏れもありそうですが、とりあえず今動かしている部分で書ける分だけ今回記事にしてみました。
今後勉強すると共に、定期的に見直していきたいです。
今回の体験で、資格取得だけでは知り得ない世界を少し垣間見ることができてとてもよかったです。
お読みいただきありがとうございました。
※本記事は2022年12月時点の情報です。

